
Latest Posts
HTTP QUERY is now standardized in RFC 10008. For backend engineers working with schema-first APIs, this provides a clean solution for a problem we have been working around for years: cacheable requests that require complex, structured input.
That matters for a protocol like ConnectRPC. Connect already tries to map RPCs onto ordinary HTTP instead of fighting the grain of the web. It supports HTTP GET for side-effect-free unary RPCs, which is great for caching, but GET forces structured request payloads into query parameters.
ConnectRPC should support QUERY as the body-carrying counterpart to GET for those same side-effect-free unary calls. Caching support across the broader web can mature over time, but the protocol shape is already useful today: structured request data belongs in the request body, not squeezed into a URL.
Why Connect Got It Right
One of the best design decisions in the Connect protocol is that it leans into standard HTTP semantics. Unlike traditional gRPC, which demands HTTP/2 and relies heavily on trailing headers, Connect maps naturally onto the HTTP infrastructure most teams already run.
That pays off operationally:
- Meaningful HTTP Status Codes: Errors map directly to standard HTTP statuses, allowing metrics to work without a specialized gRPC proxy.
- Standard Compression: Traffic relies on standard
Content-Encodingheaders (like gzip or brotli) already built into your infrastructure. - No Trailers Required: Requests pass cleanly through standard load balancers, firewalls, and HTTP/1.1 proxies without requiring end-to-end HTTP/2.
- Native Ecosystem Integration: The protocol plugs directly into Go’s standard
net/httpstack, allowing you to reuse standard middleware, multiplexers, and observability tools.
Building on this foundation, Connect allows any unary RPC marked as side-effect free (NO_SIDE_EFFECTS in Protobuf) to be invoked via HTTP GET, unlocking caching at the CDN or proxy layer.
The Problem with GET and Query Parameters
To make GET work with complex schema definitions, the protocol has to perform significant gymnastics. Because GET request bodies have no defined semantics and are routinely ignored or rejected by intermediate proxies, Connect is forced to cram structured payloads into the URL.
For a simple JSON request, the client must serialize the payload, URL-encode it, and append it as a query parameter:
GET /connectrpc.greet.v1.GreetService/Greet?connect=v1&encoding=json&message=%7B%22name%22%3A%22Buf%22%7D HTTP/1.1
Host: demo.connectrpc.com
If you use binary Protobuf or compression, the overhead increases further, requiring base64 encoding along with additional control parameters. Shoving these complex payloads into URLs creates immediate practical problems for production systems:
- Bloated URLs: Complex requests easily hit maximum URL length limits enforced by load balancers, reverse proxies, and older browsers.
- Leaky Logs: Query parameters show up in plain text in standard Nginx or Apache access logs, WAF dashboards, and observability tools. If a request contains sensitive filter criteria, teams are forced to write custom masking rules to scrub their logs.
- Encoding Friction: Maintaining a separate serialization path just for GET requests introduces branching logic into the codebase. Clients and servers must implement special handling to treat this specific verb entirely differently than the rest of the API surface.
Enter HTTP QUERY
QUERY gives HTTP the method shape this use case has been missing. Semantically, it is defined as a safe, idempotent method. Mechanically, it operates like a POST, allowing a standard request body.
If ConnectRPC adopts QUERY, the entire query parameter encoding scheme can be dropped. A QUERY request looks exactly like a POST request on the wire, keeping the payload in the HTTP body natively encoded as application/json or application/proto.
Here is how a proposed JSON-based QUERY wire request looks:
QUERY /connectrpc.greet.v1.GreetService/Greet HTTP/1.1
Host: demo.connectrpc.com
Content-Type: application/json
Connect-Protocol-Version: 1
{"name":"Buf"}
And for binary Protobuf:
QUERY /connectrpc.greet.v1.GreetService/Greet HTTP/1.1
Host: demo.connectrpc.com
Content-Type: application/proto
Connect-Protocol-Version: 1
<binary protobuf>
This is the core protocol win: QUERY lets Connect reuse the normal unary POST body format instead of maintaining a specialized GET query-encoding path.
Caching Demands QUERY-Aware Infrastructure
From a network caching perspective, QUERY is not simply “GET with a body.” RFC 10008 specifies that for a QUERY response to be cached, the cache key must incorporate the request body content alongside related metadata.
Most existing HTTP caching infrastructure is built strictly around request metadata such as the method, scheme, host, path, query string, and selected headers. Supporting QUERY requires intermediate proxies, gateways, and CDNs to inspect and hash request bodies. Until major CDNs document first-class support for body-aware cache keys, QUERY caching should be treated as experimental outside infrastructure you control directly.
The Browser Story
Browser support is not a reason to avoid QUERY; it is a reason to implement it deliberately.
Because QUERY is not a CORS-safelisted method, cross-origin browser clients require the server or gateway to allow it in preflight responses. This is a standard deployment requirement for modern APIs. Many Connect-Web deployments already require custom CORS configuration for protocol headers, content types, and credentials.
Adopting QUERY gives web clients a clean way to express search forms, filtered list views, reporting queries, and batch reads without resorting to URL hacks.
A Pragmatic Rollout Strategy
We cannot flip a switch and expect a new HTTP verb to work across the public internet immediately. The web is built on middleboxes, load balancers, strict firewalls, and managed WAFs that are inherently suspicious of unfamiliar traffic and will likely reject QUERY requests as malformed for some time.
However, many modern backend servers accept arbitrary verbs without complaint. You can verify how your current stack handles unfamiliar methods right now using httpbin.io:
$ curl -X QUERY [https://httpbin.io/status/200](https://httpbin.io/status/200) -w "%{http_code}"
200
To prove the server simply accepts the string token, you can test an arbitrary string:
$ curl -X YEET [https://httpbin.io/status/200](https://httpbin.io/status/200) -w "%{http_code}"
200
While this does not prove full RFC 10008 compliance, it confirms that the initial deployment barrier at the server application layer is low. The harder problem is teaching intermediaries, caches, and client libraries what QUERY actually means.
The most effective early deployments will target paths where engineering teams control the entire network hop: internal service-to-service traffic and browser-facing APIs behind configurable API gateways. Protocols like Connect are the ideal starting point because they can expose QUERY as an opt-in transport mechanism while the broader networking ecosystem catches up.
What QUERY Should Not Replace Yet
While QUERY is the cleaner protocol shape, a practical rollout requires clear boundaries:
- GET remains useful for small, URL-friendly requests: For simple payloads that fit naturally in a URI, GET continues to offer mature browser integration, native CDN caching, and effortless manual debugging.
- POST remains the compatibility fallback: When requests have side effects, or when traffic must route through uncooperative legacy intermediaries, POST remains the universal standard.
- QUERY starts as opt-in: Support should initially be opt-in for unary RPCs explicitly marked
NO_SIDE_EFFECTS. This option should be exposed to both server-side and web clients, backed by clear deployment guidance for CORS, gateways, and cache behavior.
The QUERY method solves a real, persistent networking problem. It is time to put it to work.
In my previous article, benchmark results showed that Go’s official protojson package was surprisingly slow. Execution profiles consistently highlighted the same bottlenecks: reflection, pointer chasing, and descriptor traversal accounted for much of the latency and memory allocation.
ProtoJSON must preserve Protobuf semantics, including custom field names, enums, presence rules, and message structure, while producing standard JSON. The official implementation uses protoreflect to dynamically walk descriptors and inspect message structures on every call.
That raised a concrete question: how much of this cost is inherent to JSON formatting, and how much comes from repeatedly resolving schema mappings at runtime?
To answer this, I built protojsonx. Moving schema resolution out of the hot path brings ProtoJSON marshaling performance close to binary protobuf and ahead of both Go’s standard encoding/json and encoding/json/v2 in these benchmarks.
An experimental faster ProtoJSON encoder and decoder for Go.
Moving Schema Work Out of the Hot Path
The official implementation discovers how to map each protobuf field to JSON while processing the message. protojsonx resolves that mapping once and stores the result as a precomputed schema layout table.
It uses that precomputed schema information in two ways:
- Runtime Table Mode: Builds flat schema layout tables once at startup initialization. This allows it to marshal and unmarshal messages using direct offset arithmetic instead of per-call descriptor traversal.
- Generated Plugin Mode: Provides a
protocplugin (protoc-gen-go-protojsonx) that bakes type-specific marshaling and unmarshaling methods directly into generated.pb.gocode, bypassing the runtime lookup layer entirely.
protojsonx is designed as a mostly API-compatible experimental alternative to Go’s official google.golang.org/protobuf/encoding/protojson package. It handles common rules including custom json_name, enums, field presence, unknown fields, oneofs, maps, and standard options (though experimental features like dynamic Any resolver callbacks are not yet supported).
Warning:
protojsonxis experimental. It passes the official Protobuf conformance suite, but it has not yet seen enough production use for me to recommend it as a drop-in replacement.
Benchmark Setup
These benchmarks do not compare identical semantics. They answer a practical question: when an application needs ProtoJSON-compatible output, how expensive is that compared with Go’s general-purpose JSON packages?
Payloads and Sizes
I used the benchmark suite from my previous article, running on Go 1.26 on an Apple M1 Pro across three payload shapes:
- Small: A flat object with 4 fields (string ID, status boolean, age integer, score float).
- Medium: A nested user signup event containing an actor object, string tags, and a metadata map.
- Large: An array repeating the Medium object 100 times.
Serialization output size matters, especially when comparing JSON and binary protobuf:
| Payload | ProtoJSON bytes | generic JSON bytes | binary proto bytes |
|---|---|---|---|
| Small | 55 B | 55 B | 25 B |
| Medium | 293 B | 291 B | 162 B |
| Large | 29,412 B | 29,201 B | 16,500 B |
The ProtoJSON and generic JSON sizes are nearly identical. Binary protobuf is significantly smaller, so binary numbers serve as a compact wire-format baseline rather than a direct format equivalent.
Compared Implementations
All tests measure end-to-end marshal and unmarshal execution times along with allocations.
- The generic JSON cases (
encoding/jsonandencoding/json/v2fromgithub.com/go-json-experiment/json) use native Go structs with equivalent fields. - The Protobuf cases use standard generated messages.
- I also included
hyperpb(a descriptor/layout-driven dynamic protobuf parser built around read-oriented offset decoding) andhyperpb.Shared(where the benchmark reuses an arena buffer). Whilehyperpbis not a ProtoJSON library, its numbers provide context on raw binary parsing overhead.
Show environment details and test command
- Go Version:
go version go1.26.3 darwin/arm64 - Machine Details: Apple M1 Pro (10-core CPU, 16GB unified memory, macOS),
GOMAXPROCS=8 - Target Library Version:
github.com/sudorandom/[email protected] - Benchmark Commit:
b8fff78c - Benchmark Source: Available in benchmarks/
- Test Execution Command:
go test -bench=. -benchmem -benchtime=5s -count=5 > results.txt
The tables report arithmetic means for ns/op, B/op, and allocs/op computed from the raw five-run output.
Marshaling Performance
Marshaling starts with an already constructed Go message, so the encoder mainly needs to walk its fields and write JSON bytes.
Show complete data table
| Format / Serializer | ns/op | Memory (B/op) | Allocations/op | Speed vs protojson |
|---|---|---|---|---|
| protojson | 2,227 ns | 1,722 B | 34 | 1.0x (Baseline) |
| encoding/json | 521 ns | 464 B | 2 | 4.3x faster |
| encoding/json/v2 | 803 ns | 608 B | 3 | 2.8x faster |
| protojsonx (Runtime Tables) | 404 ns | 320 B | 1 | 5.5x faster |
| protojsonx (Generated Plugin) | 318 ns | 320 B | 1 | 7.0x faster |
| proto.Marshal | 285 ns | 176 B | 1 | 7.8x faster |
| vtproto | 103 ns | 176 B | 1 | 21.6x faster |
| hyperpb + Shared | 1,062 ns | 744 B | 17 | 2.1x faster |
Interpreting Marshaling Results
Precomputing schema layout tables eliminates most of official protojson’s marshaling overhead. Both protojsonx modes reduce marshaling to one heap allocation in these benchmarks (64 B for small, 320 B for medium, and ~32 KB for large).
Across all payload sizes, runtime table mode gets surprisingly close to the generated plugin mode. The difference is 40 ns for the small message (142 ns vs 102 ns), and about 11% for the large case (31.1 µs vs 27.6 µs). With descriptor traversal gone, the remaining gap likely comes from interpreting the table at runtime instead of executing generated field-specific code. Projects with many generated message types will pay for that extra speed through additional generated code and a larger binary.
One result unrelated to protojsonx also stood out: encoding/json/v2 was consistently slower than v1 during marshaling (for example, 62 µs vs 41 µs on large payloads). That may reflect additional state tracking and the costs of its more flexible implementation, though the benchmark does not isolate the cause.
On the large payload, generated protojsonx took 27.6 µs, compared with 25.1 µs for proto.Marshal. I did not expect JSON encoding to get that close. For this payload, once descriptor traversal was removed, writing field names and formatted values added surprisingly little time over binary encoding.
Unmarshaling Performance
Marshaling showed that precomputed schema information eliminates most of the official implementation’s overhead. Decoding is a tougher test because avoiding reflection does not remove JSON tokenization, string parsing, or message construction.
Show complete data table
| Format / Serializer | ns/op | Memory (B/op) | Allocations/op | Speed vs protojson |
|---|---|---|---|---|
| protojson | 3,703 ns | 1,304 B | 58 | 1.0x (Baseline) |
| encoding/json | 2,937 ns | 688 B | 19 | 1.3x faster |
| encoding/json/v2 | 1,133 ns | 256 B | 4 | 3.3x faster |
| protojsonx (Runtime Tables) | 1,108 ns | 576 B | 16 | 3.3x faster |
| protojsonx (Generated Plugin) | 720 ns | 528 B | 14 | 5.1x faster |
| proto.Unmarshal | 571 ns | 560 B | 15 | 6.5x faster |
| vtproto | 322 ns | 432 B | 14 | 11.5x faster |
| hyperpb | 638 ns | 1,446 B | 5 | 5.8x faster |
| hyperpb + Shared | 290 ns | 357 B | 1 | 12.8x faster |
Interpreting Unmarshaling Results
The generated decoder pulls further ahead than I expected. Runtime tables are almost twice as slow on the small payload (267 ns vs 136 ns) and remain about 34% slower on the large one (111.1 µs vs 73.3 µs). When parsing JSON dynamically, runtime table mode looks up field mappings in a table for every incoming key, whereas generated code emits direct message-specific key matching and field assignments.
The allocation count initially looks disappointing. Generated protojsonx still performs 1,407 allocations on the large payload. In this benchmark, decoding must allocate the nested messages, slices, strings, and maps that make up the result. Many of the remaining allocations therefore belong to constructing the output message graph rather than resolving its schema.
encoding/json/v2 performed much better than v1 during decoding, nearly matching runtime-table protojsonx on the large payload (108.8 µs vs 111.1 µs). Generated protojsonx remained faster (73.3 µs), which is consistent with its ability to emit message-specific field matching and assignment code without generic reflection overhead.
Conclusion
These benchmarks suggest that much of Go’s official protojson cost comes from resolving schemas at runtime rather than from JSON formatting alone. Precomputed tables recover most of the marshaling performance, while generated code has a larger advantage during decoding, where field matching happens for every JSON key.
That does not make JSON equivalent to binary protobuf. Tokenization, number parsing, and constructing the destination message still cost time and allocations. But the results show that ProtoJSON can be substantially faster than Go’s current general-purpose implementation.
What I Need Tested Next
If you are serving JSON APIs backed by Protobuf and protojson is showing up in your profiles, run the benchmarks against your own schemas and payloads before choosing an implementation.
I’m especially interested in benchmark results from real production schemas: large repeated fields, maps, oneofs, well-known types, custom json_name usage, and edge cases beyond standard benchmark structs.
Check out the project on GitHub: sudorandom/protojsonx.
The more weird schemas, the better.
gRPC did a lot right. It turned Protocol Buffers into an API design tool, delivering typed messages, generated clients, and strict contracts. For backend networks where you control every hop, it is a fantastic tool.
But gRPC tied itself too tightly to its HTTP/2 transport model. Specifically, it built core application behavior, like delivering final application status codes via response trailers, around protocol features that browser JavaScript could not fully expose.
Browsers support HTTP/2 at the network layer, but frontend JavaScript gets a much narrower API. Standard browser tools like fetch and XHR do not expose HTTP trailers to application code in the way native gRPC depends on. This left gRPC in an awkward position: the browser was using HTTP/2 underneath, but JavaScript could not make a native gRPC call.
The Compromise: gRPC-Web
gRPC-Web was the official answer to this problem. It adjusted the wire format by encoding trailer-like data directly into the response body, allowing browser clients to function.
It worked, but the deployment story usually required a proxy, which added friction and complexity. Because ordinary gRPC servers did not speak this variant natively, you usually had to run Envoy or another gRPC-Web translation layer just to bridge browser requests into your backend.
We accepted a specialized protocol for backend-to-backend efficiency, but bringing gRPC to the web involved extra parts. gRPC-Web was treated as a weird browser variant on the side instead of a mandate to simplify gRPC itself.
Unary Calls Should Be Boring
The real mistake was letting the hardest engineering cases define the common case. Most RPCs are not bidirectional streams. They are ordinary request-response operations: create a thing, fetch a thing, update a thing.
For these unary calls, the protocol should have used standard HTTP semantics.
That means using HTTP’s existing machinery instead of recreating it inside a custom message envelope. Content-Type should say whether the body is JSON or binary protobuf. For successful unary calls, the response can use the same format as the request. Developers should be able to use application/json in browsers or local curl calls for easy debugging, while production workloads can use a binary protobuf content type for better performance. Accept-Encoding should advertise supported compression formats, and Content-Encoding should describe the compression actually used. When the body size is known, Content-Length can say how large it is. When it is not known ahead of time, the underlying HTTP version already has ways to determine where the body ends.
For unary RPCs, gRPC’s extra length prefix and compression flag were not elegant protocol design. They were streaming machinery leaking into the boring case.
You should still define your schema in protobuf, generate your clients, and get type safety. But the network layer should look like this:
curl \
-H 'Content-Type: application/json' \
-d '{"userId":"123"}' \
https://api.example.com/UserService/GetUser
If the operation naturally maps to an HTTP status, use it. If a user exists, return 200. If they do not, return 404. If the server crashes, return 500.
The standard counterargument from RPC purists is that HTTP status codes are too coarse. A 404 could mean the URL path is missing, or it could mean the requested database resource is missing. To avoid that ambiguity, gRPC often returns 200 OK for a successfully handled HTTP request and puts the RPC status in trailers.
But treating transport errors and application errors as completely separate worlds asks too much of the web. Load balancers, API gateways, CDNs, browser tools, and monitoring dashboards already understand 4xx and 5xx rates. Hiding application failures behind 200 OK makes that infrastructure less useful unless every layer becomes protocol-aware.
A web-native design should use standard HTTP status codes for coarse outcomes, then put richer domain-specific error details inside the JSON or binary response body.
Boring HTTP works. Browser dev tools understand it, standard middleboxes log it correctly, and tired engineers can debug it at 2 AM without specialized tools.
A practical protocol split would have been straightforward:
- Unary calls: Standard HTTP request-response semantics.
- Streaming calls: Framed messages over a stream-friendly transport.
The Web-Native Evolution
What I want from “the next version of gRPC” is not exotic. In fact, it already exists; it is exactly how ConnectRPC works. Connect preserves the protobuf service model and client generation, but treats unary calls as standard HTTP requests without the complexities of binary framing on top of HTTP. It proves that you can have type-safe contracts without forcing simple calls to cosplay as complex streams.
gRPC-Web should have been the moment gRPC admitted that the web was not a weird edge case. It should have been gRPC v2: protobuf contracts and generated clients on top of boring, inspectable, web-native HTTP, with special framing saved for real streaming instead of forced onto every unary call.
Instead, it became another compatibility layer. Useful, yes. But far less ambitious than it should have been.
Most Go Protobuf services get to cheat: their schemas are known at build time. protoc-gen-go turns those schemas into concrete message types, accessor methods, and runtime metadata that the protobuf runtime can use efficiently.
FauxRPC does not get that luxury. It loads user-provided schemas at runtime so it can mock arbitrary gRPC, gRPC-Web, and Connect services without asking users to install protoc, Buf, or a Go toolchain first. Without generated Go types for each schema, it has to parse and inspect payloads dynamically. This is also the case for tools like buf, grpcurl, kreya, postman, and more.
That flexibility pushed the request path toward Go’s standard dynamicpb package. dynamicpb is flexible, but it pays for that flexibility with extra allocations, descriptor lookups, and reflection-heavy access paths.
Buf introduced hyperpb, a dynamic Protobuf parser that compiles descriptors into optimized parser bytecode at runtime. I wanted to see whether it could make FauxRPC’s read path faster without giving up runtime-loaded schemas.
The short version: yes, with caveats. hyperpb is read-only, so FauxRPC still uses dynamicpb to build mock responses. But for parsing incoming requests, the performance difference was large enough to be worth the split.
Reflection-Based dynamicpb
Go’s standard dynamicpb package takes a protoreflect.MessageDescriptor and constructs a dynamic message representation at runtime.
Since message layouts are only known at runtime, dynamicpb must route field access through descriptors and generic message representations rather than generated message types and runtime metadata. This introduces additional indirection and dynamic dispatch. The cost mostly shows up in two places:
- It allocates a lot. Nested messages, repeated fields, map entries, and interface values turn into a pile of heap objects. This causes severe garbage collector (GC) pressure.
- It chases pointers. Once the decoded message is spread across many small objects, the CPU spends more time bouncing around memory instead of reading predictable, contiguous data.
Bytecode Compilation with hyperpb
Buf’s hyperpb library takes a different approach. It compiles the message descriptor into dedicated, optimized table-driven parser bytecode at runtime.
The parser avoids Go’s reflection-heavy dynamic message construction in the unmarshalling hot path, while still exposing the parsed result through the standard protoreflect APIs. In many cases, it can parse dynamic payloads at speeds close to, or even faster than, generated Go protobuf messages.
Pre-Compiling at Runtime
Because hyperpb uses a custom VM under the hood, it requires a compilation phase before you can parse any payloads. Similar to compiling a regular expression with Go’s regexp.Compile, you must compile the schema definition at runtime. hyperpb.CompileFileDescriptorSet compiles a specific message type out of a FileDescriptorSet, while hyperpb.CompileMessageDescriptor compiles an already-resolved message descriptor:
// Done once at startup/initialization
hyperMsgType := hyperpb.CompileMessageDescriptor(messageDesc)
This compilation cost is paid once per message type, so the compiled types should be cached and reused.
Moving Allocation Out of the Hot Path
The real story is not just speed. It is allocation behavior.
hyperpb provides a reusable, pre-allocated memory arena pool through hyperpb.Shared. Pairing bytecode parsing with a reusable memory arena allows you to recycle memory buffers across multiple requests. This removes most of the per-message heap churn for read-only pipelines:
shared := new(hyperpb.Shared) // Instantiated once per goroutine/worker
for _, payload := range incoming {
// Reuses the underlying pre-allocated memory arena
msg := shared.NewMessage(mType)
_ = proto.Unmarshal(payload, msg)
route(msg) // Note: Must be handled synchronously and complete before Free()
shared.Free() // Recycles the arena back to the pool
}
msg are backed by the pre-allocated pool’s memory arena, any references to those fields become invalid (and will read corrupted data or panic) after shared.Free() is called. The processing pipeline must handle the message completely synchronously (e.g., no asynchronous routing, lazy field reading, or passing to background goroutines) before the arena is recycled.Dynamic Reflection in Practice
To see how dynamicpb and hyperpb compare in code, we can use the classic ConnectRPC/Buf Eliza service schema.
A complete set of runnable examples is available in the dynamic-protobuf-in-go/go directory. It uses buf to compile the Protobuf definitions into a binary descriptor set, which is then loaded at runtime to perform dynamic serialization and reflection.
1. Compiling Protobuf Descriptors with Buf
Before using dynamic messages, we must compile the .proto schema into a FileDescriptorSet (a serialized binary image of the schemas). Using the Buf CLI, this is done with a single command:
buf build -o eliza.binpb
2. Loading Descriptors at Runtime
In Go, we read this descriptor set, unmarshal it into a descriptorpb.FileDescriptorSet, and load it into a protoregistry.Files registry:
// Read compiled schema descriptors
descriptorBytes, err := os.ReadFile("eliza.binpb")
if err != nil {
log.Fatalf("failed to read descriptor file (did you run 'buf build -o eliza.binpb'?): %v", err)
}
var fds descriptorpb.FileDescriptorSet
if err := proto.Unmarshal(descriptorBytes, &fds); err != nil {
log.Fatalf("failed to unmarshal file descriptor set: %v", err)
}
// Register files
registry, err := protodesc.NewFiles(&fds)
if err != nil {
log.Fatalf("failed to create protodesc registry: %v", err)
}
Once registered, we can look up the message descriptor by its full name and locate individual fields dynamically:
// Retrieve message descriptor for Eliza's SayRequest
sayRequestName := protoreflect.FullName("connectrpc.eliza.v1.SayRequest")
desc, err := registry.FindDescriptorByName(sayRequestName)
if err != nil {
log.Fatalf("failed to find descriptor for %s: %v", sayRequestName, err)
}
sayRequestDesc, ok := desc.(protoreflect.MessageDescriptor)
if !ok {
log.Fatalf("descriptor for %s is not a message descriptor", sayRequestName)
}
sentenceField := sayRequestDesc.Fields().ByName("sentence")
if sentenceField == nil {
log.Fatalf("failed to find 'sentence' field in %s", sayRequestName)
}
3. Dynamic Access with dynamicpb
Standard dynamicpb creates dynamic messages that support both reading and writing field values. The standard protoreflect interface is used for field access:
// Create request message dynamically
dynMsg := dynamicpb.NewMessage(sayRequestDesc)
// Set field dynamically using the reflection interface
dynMsg.ProtoReflect().Set(sentenceField, protoreflect.ValueOfString("Hello Eliza, how are you?"))
// Marshal the message to binary wire format
wireBytes, err := proto.Marshal(dynMsg)
if err != nil {
log.Fatalf("dynamicpb: failed to marshal message: %v", err)
}
fmt.Printf("Serialized bytes: %x\n", wireBytes)
// Unmarshal wire format back into a new dynamicpb message
dynMsg2 := dynamicpb.NewMessage(sayRequestDesc)
if err := proto.Unmarshal(wireBytes, dynMsg2); err != nil {
log.Fatalf("dynamicpb: failed to unmarshal message: %v", err)
}
// Get field dynamically
val := dynMsg2.ProtoReflect().Get(sentenceField)
fmt.Printf("Decoded message: %s\n", val.String())
4. High-Performance Read-Only Access with hyperpb
Because hyperpb is built for high-performance ingestion and routing, it only supports read-only access. Message descriptors must be compiled into optimized parser bytecode, and any attempt to write or mutate a message will panic:
// Compile the descriptor into hyperpb optimized message type
// Note: You should compile descriptors once at startup or pool them, not per request.
hyperMsgType := hyperpb.CompileMessageDescriptor(sayRequestDesc)
// Instantiate hyperpb message
hyperMsg := hyperpb.NewMessage(hyperMsgType)
// Unmarshal wire bytes into it (hyperpb parses without Go reflection overhead)
if err := proto.Unmarshal(wireBytes, hyperMsg); err != nil {
log.Fatalf("hyperpb: failed to unmarshal message: %v", err)
}
// Get field dynamically from hyperpb message using standard protoreflect API
hyperVal := hyperMsg.ProtoReflect().Get(sentenceField)
fmt.Printf("Decoded message: %s\n", hyperVal.String())
When running these examples (with go run .), we get the following output, verifying that both implementations decode the reflection values identically:
--- Step 1: dynamicpb (Standard Go Reflection) ---
Serialized bytes: 0a1948656c6c6f20456c697a612c20686f772061726520796f753f
Decoded message: Hello Eliza, how are you?
--- Step 2: hyperpb (Table-Driven Bytecode VM) ---
Decoded message: Hello Eliza, how are you?
--- Step 3: hyperpb + Shared (Memory Reuse Arena) ---
Decoded message: Hello Eliza, how are you?
Memory arena recycled.
By using the exact same standard protoreflect interface, hyperpb acts as a drop-in replacement for downstream read operations while executing faster and allocating much less in these benchmarks. So I wanted to check whether this held up in my own tiny benchmark goblin cave.
Performance Evaluation
I benchmarked three dynamic parsing strategies against statically generated Go Protobuf code to measure the difference in this setup:
| Variant | Description |
|---|---|
| dynamicpb | Evaluates dynamic descriptor parsing and reflection-based Protobuf handling using Go’s standard dynamicpb package. |
| hyperpb | Evaluates dynamic parsing using Buf’s table-driven hyperpb library. |
| hyperpb + Shared | Evaluates dynamic parsing using hyperpb paired with a reusable hyperpb.Shared memory arena to recycle allocations. |
| Concrete (proto) | Statically compiled Go Protobuf code (provided as a baseline comparison). |
| Concrete (vtproto) | Statically compiled, reflection-free PlanetScale vtproto code (provided as a baseline comparison). |
The benchmarks evaluate performance across three payload scales:
- Small: A flat message with 4 primitive fields (ID, status, age, score).
- Medium: A nested event message containing an actor object, tags, and a metadata map.
- Large: An array repeating the Medium event 100 times.
The source code and setup for these benchmarks are available in the dynamic-protobuf-in-go/benchmarks directory.
All benchmarks were executed on an Apple M1 Pro (darwin/arm64) using Go 1.26. Descriptor compilation was excluded from timing and performed once during benchmark initialization. Measurements represent deserialization only (proto.Unmarshal) and were collected using go test -bench=. -benchmem.
Benchmark Results
Show data table
| Benchmark (Medium Payload) | ns/op | Memory (B/op) | Allocations/op |
|---|---|---|---|
| hyperpb + Shared | 286 ns | 356 B | 1 |
| Concrete (vtproto) | 306 ns | 432 B | 14 |
| Concrete (proto) | 564 ns | 560 B | 15 |
| hyperpb | 600 ns | 1,444 B | 5 |
| dynamicpb | 2,368 ns | 2,072 B | 43 |
Analysis: Speed and Memory Efficiency
The numbers get more interesting as the payloads get larger.
1. Execution Speedup
On a Large Payload, reflection-based dynamicpb takes 241,009 ns.
- Standard
hyperpbexecutes in 24,664 ns (a 9.7x speedup). hyperpb + Sharedexecutes in 17,967 ns (a 13.4x speedup).
Note: These benchmarks measure parsing and deserialization costs only. Work performed after unmarshalling (such as downstream data manipulation or field access) is excluded.
Interestingly, both hyperpb configurations outperform compile-time generated static Protobuf code (Concrete (proto) at 54,078 ns and reflection-free Concrete (vtproto) at 35,350 ns). That is the part that surprised me. It does not mean hyperpb’s parser engine is inherently faster than generated Go code. Rather, the combination of bytecode parsing and arena-backed allocation reduces object creation costs for large nested payloads. Standard generated Protobuf still allocates individual heap objects for the nested sub-messages in this benchmark. The memory arena in hyperpb + Shared allocates this memory contiguously.
In these benchmarks, this crossover point, where dynamic parsing paired with a memory arena beats statically compiled generated code, occurs even at the Medium Payload scale. At that size, hyperpb + Shared (286 ns) already edges out reflection-free Concrete (vtproto) (306 ns).
2. Reducing Heap Allocations
The allocation statistics highlight the biggest architectural advantage. On a Large Payload:
dynamicpb: 4,117 heap allocations per message.Concrete (proto): 1,509 heap allocations.hyperpb: 12 heap allocations.hyperpb + Shared: 1 heap allocation. (The remaining allocation appears to come from the top-level message pointer escaping to the heap as aproto.Messageinterface wrapper. Because the standardproto.Unmarshalsignature requires passing an interface, this top-level escape cannot easily be avoided and prevents hitting an absolute zero allocation count.)
For hot-path event routing or proxying services, fewer allocations should translate into less GC pressure, which can help with CPU usage and tail latency under real load.
When to Use hyperpb
hyperpb is built for specific use cases. It is not a universal drop-in replacement for standard Go Protobuf code.
Ideal Use Cases
- Dynamic Gateways & Proxies: Systems receiving dynamic schemas at runtime that must inspect or forward payloads without ahead-of-time code generation.
- Developer Tooling: Tools like FauxRPC that mock interfaces, fuzz test services, or interact dynamically with user-supplied schemas.
- High-Throughput Pipelines: Pipelines with dynamic schemas where reflection overhead is a bottleneck.
Trade-offs and Constraints
- Experimental API:
hyperpbis still pre-v1, so I would avoid wrapping it deeply into public APIs without a small compatibility layer. - Platform Specificity:
hyperpbrelies on specialized runtime assembly and bytecode generators tailored for 64-bit little-endian architectures. It is officially supported only onamd64andarm64platforms. Compiling for other architectures requires the manual build taghyperpb.unsupported, which compiles a slower generic parser backend. - Read-Only vs Mutable: Reusing buffers via
hyperpb.Sharedworks best for read-only access pipelines. If you need to mutate the parsed message or pass it asynchronously to other goroutines, you must copy the data or avoid using the shared arena. This increases allocations, though still resulting in fewer than standarddynamicpb. - AOT Compilation: If your schema is known at build time, compiling your Protobuf definitions remains the best approach. Static compilation (
vtprotoor standardproto) offers strict type safety and requires no runtime bytecode compilation overhead.
Conclusion
For FauxRPC, the interesting part of hyperpb is that it offers a way to speed up the read-heavy parts of dynamic schema handling.
Even with only the request path changed, the difference was not subtle. FauxRPC still uses dynamicpb where it needs to build and mutate response messages. But for request parsing, where payloads are read-only, hyperpb is a nice optimization. The benchmarks show a clear difference: fewer heap objects, less GC pressure, and faster unmarshalling on larger payloads.
If your pipeline fits those constraints, hyperpb is worth trying.
References & Further Reading
For a deeper dive into hyperpb and Go memory arenas, check out the following resources:
- Official hyperpb Announcement:
- Deep Dives by Sunny (mcyoung):
- “Parsing Protobuf Like Never Before” (the internals of
hyperpb’s bytecode compiler design). - “Cheating the Reaper in Go” (a deep dive into the design and tradeoffs of memory arenas in Go).
- “Parsing Protobuf Like Never Before” (the internals of
Mocking APIs is one of those tasks that starts simple and quickly turns into a chore. You begin with the best intentions, hand-crafting a few JSON fixtures for your frontend tests. But microservices evolve, payloads change, and soon you’re maintaining a massive directory of stale mock files. You find yourself trying to remember if user ID 42 was the one that returns a 404, or the one that simulates a slow response.
When you’re building with gRPC or ConnectRPC, this problem gets both easier and harder. It’s easier because you have a strict schema (the Protobuf contract) to guide you. It’s harder because writing binary payloads or mock servers that conform to those schemas by hand is tedious.
In FauxRPC, I built a tool to generate fake data from Protobuf schemas dynamically. But I wanted to go further. I wanted to make mocks a natural byproduct of running your development environment. That is why I introduced Proxy Mode and Auto-Recording.
By placing FauxRPC in front of a real upstream service, it acts as a smart proxy: intercepting traffic, forwarding it to the upstream server, and writing out reusable mock stubs to disk. It even generates intelligent matching rules automatically.
Here is how it works under the hood.

The Auto-Recording Workflow
Rather than thinking about mocks as a separate coding chore, FauxRPC integrates mock generation directly into your existing development flow:
- Start FauxRPC in proxy mode in front of a staging or local backend server.
- Interact with your application normally in the browser or via API clients.
- Capture traffic automatically as FauxRPC records every request and response into the
stubs/directory. - Commit the generated stubs to Git along with your code changes.
- Run your CI test suite against FauxRPC using those recorded stubs, ensuring fast, offline, and reproducible test runs.
Zero-Configuration Reflection
Normally, running a mock server requires you to supply the schema files. You have to pass paths to your .proto files or compiled descriptor sets (.binpb). That’s fine for a CI environment, but during local development, dragging files around and keeping them in sync is a pain.
If you start FauxRPC in proxy mode without specifying a schema:
fauxrpc run --proxy-to=localhost:8080 --record-dir=stubs/
FauxRPC uses gRPC Server Reflection to discover the schema dynamically from the upstream server on startup.
Behind the scenes, FauxRPC performs a few key steps during this schema discovery phase:
- It connects to the upstream and queries the reflection service using
ListServicesto list all endpoints. - For each service, it fetches the file descriptors using
FileContainingSymbol. - It recursively collects the raw file descriptors (
FileDescriptorProto), deduplicating common dependencies (likegoogle/protobuf/timestamp.proto). - It compiles the gathered descriptors into a
FileDescriptorSetand registers them in FauxRPC’s registry.
This means FauxRPC is ready to handle, translate, and mock any method defined on the upstream server with absolutely zero configuration.
Because the schema is discovered directly from the running service, the proxy automatically stays in sync with upstream changes. No descriptor files need to be exported, committed, or manually refreshed—as your API evolves, FauxRPC adapts instantly.
The Multi-Protocol Proxy Engine
FauxRPC is designed to work as a multi-protocol translator. A frontend might communicate using ConnectRPC (over JSON), while the upstream service is a pure gRPC service using binary Protobuf.
To achieve this, FauxRPC sets up a ConnectRPC client using a custom dynamicProtoCodec for proxying. This codec uses Go’s protobuf reflection (dynamicpb.Message) to encode and decode payloads on the fly using the schemas retrieved during the reflection phase.
- Unary calls: The proxy reads the request, forwards it using the client, intercepts the response, and writes it back.
- Streaming calls (client, server, and bidi): To handle streams, FauxRPC uses
FrameTrackerobjects. The tracker forwards frames in real time so there is no added latency, but it keeps a copy of the sequence in memory for logging and recording. - Metadata and Headers: When forwarding headers via
copyHeaders, FauxRPC filters out protocol-level headers (likecontent-type,grpc-status, and Connect-specific protocol headers) to let the underlying transport layer handle them cleanly. It also automatically masks sensitive headers (e.g.Authorization,Cookie,X-API-Key) with*****to avoid leaking production keys or user credentials into logs or stubs.
Graceful Fallbacks for Parallel Teams
In a fast-moving team, schemas are often updated before the code is ready. A backend engineer might merge a .proto change adding a new endpoint, but the actual implementation won’t land for days. Normally, this blocks the frontend engineers who need that endpoint to build the UI.
FauxRPC’s Fallback Mode solves this problem directly.
If the upstream server returns an Unimplemented error code, the proxy doesn’t just pass that error to the client. Instead, it enters fallback mode:
- It checks the local stub database to see if a mock stub matches the request.
- If no stub is found, it automatically generates realistic fake data (leveraging
protovalidateannotations if they are present in the schema). - The fake response is returned to the client.
To the frontend, the endpoint looks and acts like it’s fully implemented. The frontend team keeps coding, completely unblocked by backend delays.
Auto-Recording Stubs
Writing mock stubs by hand is the worst part of API mocking. In proxy mode, FauxRPC can automate this entirely when you pass the --record-dir flag:
stubs/
└── connectrpc.eliza.v1.ElizaService/
├── Say.json
└── Introduce.json
As you interact with your upstream service, FauxRPC intercepts the requests and responses, automatically writing them to disk as structured JSON or YAML files matching your service hierarchy.
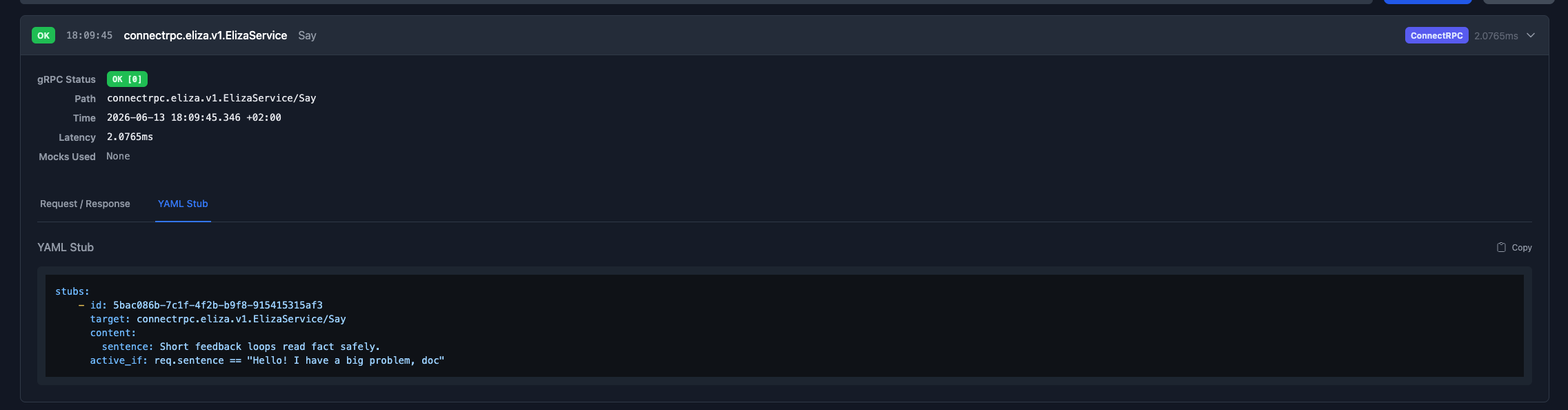
For example, a recorded stub might look like this:
{
"id": "c85d8869-ad10-449e-ba63-2287f7401c10",
"target": "connectrpc.eliza.v1.ElizaService/Say",
"active_if": "req.sentence == \"hello\"",
"content": {
"sentence": "Hello! How can I help you today?"
}
}
Because these files are saved directly in your codebase, you can commit them to Git and immediately use them as your mock suite in CI/CD pipelines or integration tests. There is no extra setup: just run your application, click around your frontend, and your API mock stubs are generated for you.
A Protobuf-Native Dashboard for Curation
Having an automated directory of stubs is a massive time saver, but you still need a way to easily curate and manage them. The developer dashboard in FauxRPC (served at http://localhost:6660/fauxrpc when running with --dashboard) gives you exactly that.
The dashboard captures your live traffic history so you can view the raw JSON payload of any logged request. From there, you can copy a pre-compiled FauxRPC YAML stub, along with its generated active_if matcher, directly to your clipboard. This gives you the ability to carefully curate your stub directory while still completely bypassing the need to hand-write them yourself.
This dashboard interface is powered by Protodocs, which displays native protobuf schemas directly inside FauxRPC. Because it understands protobuf natively, you can view your packages, messages, and services, and use a built-in API explorer to run test calls (including unary and streaming APIs) directly from the browser without needing complex local Envoy or gRPC-Web proxy configurations.
Generating Intelligent CEL Matchers
When you are curating these recorded stubs, they are only useful if they match the right request parameters. If you search for user ID 12, you want the stub that returns Alice. If you search for user ID 42, you want the stub that returns Bob.
Whether auto-saved to disk or copied from the dashboard, FauxRPC automatically compiles request shapes into Common Expression Language (CEL) matching rules by examining the request metadata and payload:
- It ranges over the fields set on the request message.
- It ignores complex fields (nested messages, lists, and maps) to keep the generated rules readable.
- For primitive fields (like strings, booleans, and integers), it formats the values into CEL literals.
- It joins these field checks with
&&.
For example, if you send a request where name is “Alice” and age is 30, FauxRPC automatically generates:
active_if: req.name == "Alice" && req.age == 30
When a subsequent request comes in, FauxRPC compiles and evaluates this expression against the request payload. If it evaluates to true, the stub is served.
Recorded Stub Formats
FauxRPC formats these stubs into three distinct kinds based on the call type:
Unary / Client-Streaming Success
For successful unary calls, it records the response payload:
{
"id": "c85d8869-ad10-449e-ba63-2287f7401c10",
"target": "connectrpc.eliza.v1.ElizaService/Say",
"active_if": "req.sentence == \"hello\"",
"content": {
"sentence": "Hello! How can I help you today?"
},
"priority": 10
}
Unary / Client-Streaming Error
If the upstream returned an error, FauxRPC records the status code and message so you can mock error states:
{
"id": "18fd7d9e-108c-4a37-bcfc-fa8d7a12ad4f",
"target": "connectrpc.eliza.v1.ElizaService/Say",
"active_if": "req.sentence == \"trigger error\"",
"error_code": 3,
"error_message": "invalid sentence structure",
"priority": 10
}
Server-Streaming / Bidirectional Streaming
For streaming APIs, it records the sequence of frames, mimicking latency with a default delay, and captures trailing errors:
{
"id": "a97df11b-7a31-4b10-8b4b-6f81e3a1f810",
"target": "connectrpc.eliza.v1.ElizaService/Introduce",
"active_if": "req.name == \"Bob\"",
"stream": {
"items": [
{ "content": { "sentence": "Hi Bob!" }, "delay": "100ms" },
{ "content": { "sentence": "I am Eliza." }, "delay": "100ms" },
{ "error": { "code": 5, "message": "session lost" } }
]
},
"priority": 10
}
Summary
FauxRPC’s proxy and recording capabilities bridge the gap between static mock servers and real-world backend services. By discovering schemas through reflection, handling dynamic protocol translation, falling back to fake data, and generating intelligent CEL matchers automatically, it takes the busywork out of API mocking.
Traditional mocks drift because they are maintained separately from the systems they represent. By recording real traffic, discovering schemas automatically, and falling back to generated data when necessary, FauxRPC keeps mock environments aligned with production behavior while dramatically reducing the amount of manual work required. It turns mocks from a maintenance chore into a natural byproduct of running your development environment.
Featured Posts
Right now, thousands of routers are arguing about how to reach each other. That’s expected. It’s how the Internet works. This website wouldn’t load without it. BGP (Border Gateway Protocol) continuously announces and withdraws prefixes, adjusting how traffic moves globally. Most people see URLs and apps; routers see prefixes and AS paths.
I made a map that lets us listen in on this conversation, but in a relaxing, aesthetically pleasing way.
In my last post, I mentioned a websocket-based streaming API from RIPE. At the time, I set it aside. Soon, it became my obsession and the live view was born. While this visualization occasionally stumbles into being practically useful for spotting global outages, my primary requirement was simply to build a really cool looking map.
You can check out the source code for this project on GitHub or watch the map in action on my YouTube channel or here:
What are we looking at?
This map is a live visualization of the Border Gateway Protocol (BGP). This is the “language” routers use to talk to each other and decide the best path for your data to travel across the globe.
Imagine a router trying to find the best way to send traffic to Google. It receives multiple path advertisements from its neighbors, and it has to pick the most efficient route:

Every pulse on the map represents a real routing update. Sometimes it’s routine churn. Sometimes it’s maintenance, an outage, or a path change somewhere along the way.
The Global Game of Telephone
To understand why the map pulses, you have to look at how routers talk. BGP is a path-vector protocol, which is effectively a global game of telephone. When a network (an Autonomous System, or AS) wants to be found, it tells its immediate neighbors, who tell their neighbors, and so on.
- The Announcement: When a router in Tokyo says, “I have a path to
8.8.8.0/24,” it sends an Update to its peers. Every peer that hears this stamps the message with its own ID before passing it along. This list of stamps is called the AS Path. - The Selection: Routers generally prefer the shortest path. If an observer in New York hears the same news from London (2 hops) and Sydney (5 hops), it will automatically choose the shorter London route. On the live map, you will see this selection light up as a purple pulse.
- The Withdrawal: If a fiber line is cut, for example, the router sends a Withdrawal. This is where the game of telephone gets frantic. Neighbors start checking their old notes: “Wait, I can’t go through London anymore? What about that longer path through Sydney I heard about earlier?”
Here is how that “envelope” looks as it travels from Tokyo to New York. Notice how the path grows longer at every step.

Because routers often wait a few seconds before passing news along (to avoid “vibrating” the whole internet with every tiny hiccup), these updates arrive in waves. On the live map, this looks like a ripple of activity starting at the origin and washing over the globe as the “signatures” accumulate.
Spotting a BGP Flap
If you are watching the map and suddenly see a wave of pulses lighting up all over the world at the exact same time, you might be witnessing a BGP flap.

In networking, flapping happens when a route rapidly appears and disappears. Imagine a misconfigured router or a loose fiber cable. The router yells to the Internet, “I have a path to Google!” only to drop the connection a second later and say, “Never mind, it is gone”. That single localized hiccup doesn’t stay local. It ripples outward as routers everywhere recalculate their paths. To keep the whole system from grinding to a halt, modern routers use Route Flap Damping. This essentially puts the noisy network in a time-out until it proves it can stay stable.
Decoding the Pulses
When you see those colored pulses popping off on the map, they represent BGP updates processed through a multi-stage classification engine. Rather than just showing raw protocol messages (which is what the earlier version of the map did), the map categorizes events into four distinct colors based on their behavior and potential impact.

Anomalies and Behaviors
The classification engine also maps events into Level 2 categorizations (anomalies) based on heuristics applied over recent activity windows. To make sense of the noise, the multi-stage engine uses specific triggers to drop these events into the four colored buckets before presenting them on the map. These fall into four severity tiers:
| Severity Tier | Color | Description |
|---|---|---|
| Critical | Red | Significant routing failures, such as a prefix sustaining multiple withdrawals with no announcements, or path violations that suggest a route leak. |
| Bad | Orange | Highly volatile or inefficient behavior, including rapid “flapping” of routes, excessive “babbling” (a term I coined for this project) with unchanged attributes, or frequent next-hop changes. |
| Normal / Policy | Purple | Standard routing adjustments, such as traffic engineering (Policy Churn), path length oscillations, or the natural “Path Hunting” process where routers explore alternatives during convergence. |
| Normal / Discovery | Blue | Routine background noise, including standard prefix origination or redundant gossip pulses that keep routing tables current. |
When you zoom out and see all those colors firing at once, the true scale of the Internet comes to life. It tells the story of over 70,000 independent networks coordinating in real time.
What else is on the map?
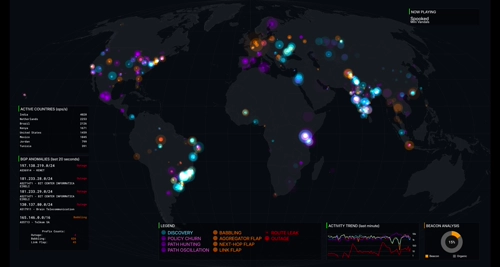
To make sure the map isn’t just a wall of moving dots, I included several dashboard elements that provide context to the chaos:
| Preview | Description |
|---|---|
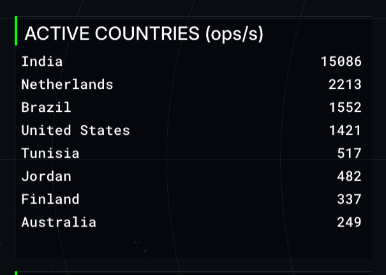 | Ranks the countries currently experiencing the highest volume of network updates. It is an instant look at where in the world the most “routing churn” is happening at any given moment. |
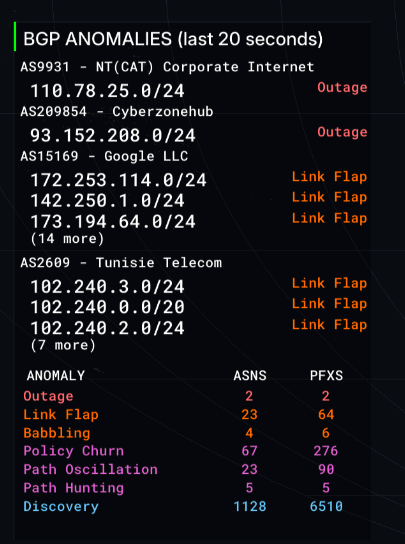 | Tracks the specific network blocks that have the worst anomalies that we’ve detected. Great for spotting outages or a flapping link. Another name for this is the networking “wall of shame”. |
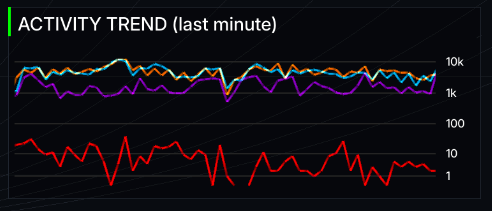 | A rolling 60-second activity graph. It tracks whether activity is spiking or calming down, letting you see the difference between routine background noise and a massive routing event. |
| A dynamic donut chart separating “Organic” traffic from “Beacons” (special test signals sent out by researchers). It helps show how much activity is natural versus intentional measurement. More on this below. | |
 | The current background music track. |
Path Hunting and Anycast
When I first started watching the live data, I was confused by why a single localized outage would trigger a massive global explosion of pulses.
I’ve since learned this is likely due to a phenomenon called “Path Hunting.” When a route dies, the Internet doesn’t instantly agree it’s gone. Instead, routers desperately try to find backup paths. They’ll try a longer route, fail, try an even longer one, fail again, and generate a new BGP update every single time. Those massive bursts of purple pulses are basically the routers “thinking out loud” as they scramble to route around the damage.

This scramble to find backup paths can occasionally leave behind an interesting anomaly known as a “BGP zombie.” If a router fails to process a withdrawal message due to a software bug or slow propagation, it will stubbornly keep announcing a dead path to its neighbors, creating a localized black hole for traffic. Cloudflare has a great write-up on hunting down these undead routes if you want to fall down that rabbit hole.
Anycast routing amplifies this chatter even further. Huge networks (like Google or Cloudflare) announce the exact same /24 prefix from dozens of different physical locations globally so their services are fast everywhere. But if a major transit provider drops a peering session, or a provider intentionally shifts traffic away from a datacenter for maintenance, thousands of routers might suddenly decide to shift their traffic to a different Anycast node all at once. The result is a sudden surge of routing adjustments across the map.

RIPE RIS Beacons and Anchors
While building the “Most Active Prefixes” list, I kept noticing the exact same thing: /24 subnets were overrepresented on the leaderboard.
A /24 (256 IPs) is effectively the smallest globally routable unit, so most churn naturally happens at that granularity.
But there was another reason for seeing the same /24 subnets appearing on the list. Not all activity on the map comes from failing links or organic traffic shifts. There is also intentional ‘breakage’ happening behind the scenes to test BGP propagation.
It turns out RIPE RIS operates Routing Beacons. Routing Beacons are prefixes deliberately announced and withdrawn on a fixed schedule, typically every two hours. One of them announces and withdraws every 10 minutes. Researchers use these beacons as a controlled signal inside the global routing table to study BGP propagation and convergence. To make the activity list useful, I had to write logic to classify and filter these beacons out of the ranking.
RIPE also runs “Anchors” alongside these beacons. While a beacon prefix constantly flips on and off, an anchor is a prefix permanently announced from the exact same physical router. This gives researchers a stable control group. They can compare the volatile beacon traffic against a baseline of stable routing from the identical location.
I eventually added a Beacon Analysis view that separates “organic” updates from beacon-driven ones. It makes the metrics more accurate and highlights how much traffic is from deliberate live validation.
BGP Babbling and Attribute Churn
So if a burst of updates isn’t a dying link, a desperate search for a backup path, or a research beacon, what else could it be? Sometimes a network is just fidgeting. I call this babbling. While not an official industry term, it perfectly describes the constant, repetitive “talk” of updates that don’t actually change anything meaningful about the route.
I caught a great example of this while watching the stream. A Finnish fiber provider (AS43016) was firing off nearly 100 pulses per second, and this went on for days. The raw data showed the route wasn’t actually dropping. Instead, a single piece of metadata called the Aggregator ID just kept flipping back and forth.
This creates a localized flurry of activity. Some router somewhere was probably misconfigured and couldn’t make up its mind about how to summarize its own network. Every time it changed its mind, even by a single bit, it had to update every other router on Earth. Standard monitoring tools usually miss these “attribute flaps” because the network stays perfectly reachable. But on the map, they paint a very clear picture: a constant, rhythmic heartbeat of orange “bad behavior” pulses.
I built a tool to debug noisy prefixes like this. It aggregates BGP update stats and tries to diagnose the root cause, such as path oscillation, a flapping link, or heavy Anycast routing. Here is the output for our problem child over at AS43016:
$ just debug-prefix 195.155.146.0/24
BGP Prefix Monitor Stats (Running for 293.4s)
--------------------------------------------------
Announcements: 4576 (15.60/s)
Withdrawals: 1422 (4.85/s)
Total Msgs: 5101 (17.39/s)
Unique Peers: 310
--------------------------------------------------
GLOBAL CHURN EVENTS:
AS-Path Changes: 2275
Community Changes: 3259
Next-Hop Changes: 0
Aggregator Flaps: 0
Path Length Flaps: 1255
--------------------------------------------------
LIKELY CONCLUSIONS:
- Path Length Oscillation (Route is toggling between different path lengths)
- BGP Babbling (Excessive update rate detected)
--------------------------------------------------
Top 5 Churning Peers:
187.16.220.216: 149 attribute changes
5.188.4.211: 142 attribute changes
103.152.35.254: 142 attribute changes
177.221.140.2: 138 attribute changes
154.18.4.110: 132 attribute changes
At the time of publishing, this prefix is still babbling away. This script became the basis for the classification engine that I discuss later on in the article.

Making the map
Handling 30,000+ BGP updates per second takes more than plotting points on a canvas. The project is written in Go for its concurrency model and relies on Ebitengine for hardware-accelerated 2D rendering.
Why a Stream?
I originally planned to build this as a standard web frontend, similar to my previous map. However, I hit two massive walls almost immediately.
The first problem was the sheer volume of data. BGP updates can easily peak at over 30,000 events per second. Forcing a web browser to process that firehose while maintaining a smooth 30 FPS with complex blending is just not in the cards today.
The second problem was scaling. If the map actually got popular, having thousands of browsers opening individual websocket connections to the RIPE RIS-Live service would be a disaster. It is wildly inefficient, and accidentally DDoSing a service designed to monitor Internet stability was not on my to-do list.
Here is what that scenario looks like:

To protect the RIPE service from being overwhelmed, the logical next step was to put a middleman in place to handle the multiplexing. This led me to a standard client-server architecture:

Multiplexing solves the connection problem, but it completely ignores the browser rendering issues I was having. To guarantee a smooth 30 FPS for everyone without melting their CPUs, I decided to bypass the browser canvas entirely. I pivoted the architecture to a centralized YouTube stream:

Now I had a choice. Scenario 1 was dead on arrival because it could make the operators of RIPE RIS-Live very sad and potentially angry. That left me with the choice between building a complex backend service to multiplex that single RIPE connection to all my users (Scenario 2), or completely changing how people view the map by streaming to YouTube (Scenario 3). I went with the latter option.
Rendering the entire visualization on my own server and broadcasting it guarantees that every viewer gets the exact same high-fidelity experience, regardless of their hardware. It is easy to run on a TV where the browser version isn’t really viable. This pivot also made the tech stack an obvious choice. Once I started experimenting with Ebitengine, hardware-accelerated rendering in Go gave me crisper, far more fluid visuals than I could ever squeeze out of a standard browser canvas.
The downside is reduced interaction: no zooming, no toggling UI, no customization. I think this tradeoff was ultimately worth it, but I just want to note what I lost from making this dramatic change in architecture.
Flattening IP Space
To map a BGP update to a geographic location, you need reliable IP-to-region data. I am currently only focusing on IPv4, and that data comes from five Regional Internet Registries (RIRs). Each registry publishes large and sometimes overlapping delegated stats files.
Fragmented lookups across raw datasets might be fine for offline processing, but we have a strict frame rate budget. If the engine had to search through five separate datasets for every single update, the visualization would stutter. At 30,000+ updates per second, efficiency is pretty important.
To solve this, I preprocess all the data upfront using a sweep-line algorithm. Each IP range acts as a segment on a 1D number line. The algorithm walks across this space, resolves any overlaps between registries, and collapses millions of ranges into a single, clean, non-overlapping index.
For example, take two overlapping registry entries:
- Range A (ARIN):
10.0.0.0to10.0.0.255 - Range B (RIPE):
10.0.0.128to10.0.1.255
The algorithm flattens these into three distinct, non-overlapping segments:
10.0.0.0to10.0.0.127(ARIN only)10.0.0.128to10.0.0.255(Conflict resolved)10.0.1.0to10.0.1.255(RIPE only)
This preprocessing seems like overkill, but it’s worth it since it makes lookups super cheap. I back this index with BadgerDB and a DiskTrie for high-performance persistent storage. This allows the engine to track “seen” prefixes seamlessly across different sessions without eating up memory.
Managing the Firehose
BGP updates arrive continuously, and during route flapping events the volume spikes hard.
To keep the visualization readable without becoming an incomprehensible mess, the pipeline waits 10 seconds to ensure a withdrawal isn’t just a rapid path re-convergence, and paces the visual output so spikes are emitted smoothly every 500ms.

Aesthetics and Motion
Animations use interpolation instead of snapping to the next state. For parts of the map which update infrequently, I wanted to highlight that a change occurred. For that, I added a “glitch” effect to the “Top Activity Hubs” and “Most Active Prefixes” to make it more obvious and to add to the cyberpunk aesthetic. These effects add polish, but too much motion detracts from the vibes of the map. Finding that balance took restraint and a surprisingly large amount of experimentation.
The pulses are what actually bring the data to life. In the engine, each pulse is a simple generated glow texture. I add a bit of spatial jitter so concurrent events do not stack perfectly on top of each other, and I scale their sizes logarithmically so massive data spikes do not turn the map into a solid wall of color.
The colors map directly to the severity tiers: red for critical events, orange for bad behavior, purple for policy churn and hunting, and blue for routine discovery. Because they use additive blending, overlapping pulses naturally create a bright hotspot over regions with a ton of routing activity. They pop onto the map, expand, and fade out smoothly. Managing this entire visual lifecycle efficiently is what keeps the map feeling dynamic without tanking the frame rate.
Animation of BGP events in Europe
The Mollweide Projection
Mercator would have been easy, but it heavily distorts size near the poles. For a global activity map, that felt misleading.
I chose the Mollweide projection.

This is an equal-area projection, which means it accurately represents the physical footprint of different regions. It produces a world view that still feels familiar without exaggerating high-latitude areas.
More Meaningful Events
Raw BGP messages only tell us two things: a route was announced, or a route was withdrawn. So how does the dashboard know when to declare a ’link flap’, a ‘route leak’, or a massive ‘outage’? The short answer is that I built a classification engine that takes the pattern of raw announce/withdrawal updates that BGP provides and converts them more meaningful events. Some kinds of events are easier to detect than others.
Route leaks are a great example of how messy this can get. Initially, I tried to validate routes using databases like Cloudflare’s RPKI portal, specifically hooking into their rpki.json endpoint. The goal was to check if the announcements for networks actually matched their registered ASNs. In practice, this resulted in way too many false positives because a massive number of announcements just were not matching the registered ASNs. If I had kept that logic, the map would have been permanently covered in red alert pulses.
Because of the noise, I ended up implementing a check for the valley-free routing principle. To understand why this works, we have to look at how BGP treats business relationships. BGP routing policies are built around who is paying whom. A network typically has providers it pays for transit, customers who pay it for access, and peers it swaps traffic with for mutual benefit. The valley-free rule dictates that a network should never act as a free transit bridge between two of its providers or peers.
Imagine a small regional network buys internet access from both AT&T and Verizon for redundancy. AT&T shares its global routing table with this small network so it knows where to send data. If that small network accidentally announces all of those AT&T routes to Verizon, it is inadvertently telling the entire internet to send all traffic between Verizon and AT&T through its local routers. Traffic would flow down from Verizon, into the small regional network, and back up to AT&T. That “down and back up” path is what creates the valley shape in the AS path. Because that small network does not have the capacity to handle global Tier-1 traffic, it immediately gets crushed under the weight of the data. The network drops packets and causes a massive localized internet outage, which is a classic route leak.


So, when the classification engine sees an AS path that violates this principle by dipping down into a lower-tier network and back up to a major provider, the system flags it as a route leak. While it serves as a decent baseline, I am generally uncertain about relying solely on this method. It is definitely a part of the classification engine that I want to explore and refine over time.
Other rules are slightly more straightforward:
| Event | Detection Trigger |
|---|---|
| Outage | >= 3 withdrawals, 0 announcements |
| Route Leak | path contains Tier-1 to non-Tier-1 to Tier-1 |
| Link Flap | > 5 withdrawals, announce:withdrawal ratio < 2.5 |
| Babbling | High volume, unchanged attributes |
| Next-Hop Flap | >= 5 next-hop changes, stable path length |
| Aggregator Flap | > 10 AGGREGATOR changes |
| Policy Churn | Elevated attribute changes |
| Path Oscillation | Frequent path length switching |
| Path Hunting | Increasing path length, then withdrawal |
| Discovery | Prolonged announcements, few changes |
To make these determinations, the engine analyzes the last five minutes of event data. Once classified, a prefix holds its state for ten minutes before being reevaluated. This means a prefix might eventually downgrade from a Link Flap to a routine Discovery. Outage states are the sole exception and clear immediately upon any new announcement. These initial rules are just a baseline I plan to refine as the project evolves.
Here is the final result, which I’ve gazed at for far too long already:
This project turned into a deeper dive into BGP than I expected. Watching as routing updates happen live exposes patterns that are impossible to find with a static snapshot. It has been a rewarding project and I am extremely happy with the result.
So please, toss the live stream on your TV, sit back, relax, and watch the Internet route the world’s network traffic as you listen to relaxing lofi in the background.
For the past few years, I’ve been trying to make the physical reality of the Internet visible with my Internet Infrastructure Map. This map shows the network of undersea fiber-optic cables along with peering bandwidth, grouped by city. I update the map annually, but I don’t want to just pull the latest data and call it a day. In this post I discuss how the map evolved this year and what I did to make it happen, but you can skip to the good part by viewing it here: map.kmcd.dev.
For the 2026 edition, I wanted to better answer the question: where does the Internet actually live? By layering on BGP routing tables alongside physical infrastructure data, I’m now closer to answering that question.
The result is a concept I call “Logical Dominance.” Each city’s dominance is calculated by summing total address space of IPv4 subnets that are “homed” in that city. How can I tell where IP addresses are homed? This required analyzing global routing tables to trace IP ownership back to specific geographies. Read on to find out how I accomplished this!


How the Internet Routes Traffic
Previous versions of the map focused on physical infrastructure: cables and exchange points. The physical path is only half the story. To understand how data moves, we have to look at BGP (Border Gateway Protocol).
BGP is the protocol that distinct networks, known as Autonomous Systems (AS), use to announce which IP addresses they own and how to reach them. If the cables are the hardware, BGP is the software that ties the Internet together. Cloudflare has an excellent primer.
When you load a webpage, your request doesn’t just “know” the path. Your ISP’s routers consult the global BGP routing table to decide the best next hop. Visualized, it looks a little bit like this:

In this state, the route from Router -> Netstream (AS8283) -> Google (AS15169) was chosen, at least for now. The underlying routes of the global Internet change thousands of times per second, constantly reshaping the topology.
Sources of BGP Data
To visualize this layer, we need access to routing tables. I explored three ways to get this data, each with its own trade-offs between real-time visibility and historical context.
Query a Looking Glass
We can connect to public routers via projects like University of Oregon Route Views. These allow you to telnet in and run standard CLI commands like show ip bgp to see exactly what a backbone router sees.
BGP routes for 8.8.8.8 (click to expand)View on GitHub
$ telnet route-views.routeviews.org 23
**********************************************************************
RouteViews BGP Route Viewer
route-views.routeviews.org
RouteViews data is archived on https://archive.routeviews.org
This hardware is part of a grant by the NSF.
Please contact [email protected] if you have questions, or
if you wish to contribute your view.
This router has views of full routing tables from several ASes.
The current list of all RouteViews peers is at
https://www.routeviews.org/peers/peering-status.html
NOTE: If you are using macOS and seeing the error message
"no default Kerberos realm" when logging in, you may want to
add "default unset autologin" to your ~/.telnetrc
To login, use the username "rviews".
**********************************************************************
User Access Verification
Username: rviews
route-views>show ip bgp 8.8.8.8
BGP routing table entry for 8.8.8.0/24, version 941738530
Paths: (16 available, best #15, table default)
Not advertised to any peer
Refresh Epoch 1
4826 15169
114.31.199.16 from 114.31.199.16 (114.31.199.16)
Origin IGP, localpref 100, valid, external
Community: 4826:5203 4826:6510 4826:52032
path 7F168F059710 RPKI State valid
rx pathid: 0, tx pathid: 0
Refresh Epoch 1
57866 15169
37.139.139.17 from 37.139.139.17 (37.139.139.17)
Origin IGP, metric 0, localpref 100, valid, external
Community: 57866:200 65102:56393 65103:1 65104:31
unknown transitive attribute: flag 0xE0 type 0x20 length 0x30
value 0000 E20A 0000 0065 0000 00C8 0000 E20A
0000 0066 0000 DC49 0000 E20A 0000 0067
0000 0001 0000 E20A 0000 0068 0000 001F
path 7F15A63304E8 RPKI State valid
rx pathid: 0, tx pathid: 0
Refresh Epoch 1
6939 15169
64.71.137.241 from 64.71.137.241 (216.218.253.53)
Origin IGP, localpref 100, valid, external
path 7F1555102CB8 RPKI State valid
rx pathid: 0, tx pathid: 0
Refresh Epoch 1
20130 6939 15169
140.192.8.16 from 140.192.8.16 (140.192.8.16)
Origin IGP, localpref 100, valid, external
path 7F1588A8BD60 RPKI State valid
rx pathid: 0, tx pathid: 0
Refresh Epoch 1
3333 1257 15169
193.0.0.56 from 193.0.0.56 (193.0.0.56)
Origin IGP, localpref 100, valid, external
Community: 1257:50 1257:51 1257:3528
path 7F16B16DD098 RPKI State valid
rx pathid: 0, tx pathid: 0
Refresh Epoch 1
7018 15169
12.0.1.63 from 12.0.1.63 (12.0.1.63)
Origin IGP, localpref 100, valid, external
Community: 7018:2500 7018:37232
path 7F1626828FD8 RPKI State valid
rx pathid: 0, tx pathid: 0
Refresh Epoch 1
20912 15169
77.39.192.30 from 77.39.192.30 (77.39.192.1)
Origin IGP, localpref 100, valid, external
Community: 20912:65002 20912:65022
path 7F15D19801C0 RPKI State valid
rx pathid: 0, tx pathid: 0
Refresh Epoch 1
3356 15169
4.68.4.46 from 4.68.4.46 (4.69.184.201)
Origin IGP, metric 0, localpref 100, valid, external
Community: 3356:3 3356:86 3356:576 3356:666 3356:901 3356:2012
path 7F1679EB7640 RPKI State valid
rx pathid: 0, tx pathid: 0
Refresh Epoch 1
3549 3356 15169
208.51.134.254 from 208.51.134.254 (67.16.168.191)
Origin IGP, metric 0, localpref 100, valid, external
Community: 3356:3 3356:22 3356:86 3356:575 3356:666 3356:901 3356:2011 3549:2581 3549:30840
path 7F16C7D32728 RPKI State valid
rx pathid: 0, tx pathid: 0
Refresh Epoch 1
101 15169
209.124.176.223 from 209.124.176.223 (209.124.176.224)
Origin IGP, localpref 100, valid, external
Community: 101:20400 101:22200 101:24100
path 7F1648388978 RPKI State valid
rx pathid: 0, tx pathid: 0
Refresh Epoch 1
1351 15169
132.198.255.253 from 132.198.255.253 (132.198.255.253)
Origin IGP, localpref 100, valid, external
path 7F15C90D61B8 RPKI State valid
rx pathid: 0, tx pathid: 0
Refresh Epoch 1
3257 15169
89.149.178.10 from 89.149.178.10 (213.200.83.26)
Origin IGP, metric 10, localpref 100, valid, external
Community: 3257:8052 3257:30306 3257:50001 3257:54900 3257:54901
path 7F154665E650 RPKI State valid
rx pathid: 0, tx pathid: 0
Refresh Epoch 1
2497 15169
202.232.0.2 from 202.232.0.2 (58.138.96.254)
Origin IGP, localpref 100, valid, external
path 7F1660B0A1C8 RPKI State valid
rx pathid: 0, tx pathid: 0
Refresh Epoch 2
3303 15169
217.192.89.50 from 217.192.89.50 (138.187.128.158)
Origin IGP, localpref 100, valid, external
Community: 3303:1004 3303:1007 3303:3067
path 7F16E10C0508 RPKI State valid
rx pathid: 0, tx pathid: 0
Refresh Epoch 1
8283 15169
94.142.247.3 from 94.142.247.3 (94.142.247.3)
Origin IGP, localpref 100, valid, external, best
Community: 8283:1 8283:101 8283:102
unknown transitive attribute: flag 0xE0 type 0x20 length 0x30
value 0000 205B 0000 0000 0000 0001 0000 205B
0000 0005 0000 0001 0000 205B 0000 0005
0000 0002 0000 205B 0000 0008 0000 001A
path 7F16DC0E5B28 RPKI State valid
rx pathid: 0, tx pathid: 0x0
Refresh Epoch 1
49788 12552 15169
91.218.184.60 from 91.218.184.60 (91.218.184.60)
Origin IGP, localpref 100, valid, external
Community: 12552:10000 12552:14000 12552:14100 12552:14101 12552:24000
Extended Community: 0x43:100:0
path 7F15CAD0C378 RPKI State valid
rx pathid: 0, tx pathid: 0
route-views>⏎
These paths often carry metadata called BGP Communities. These are optional tags that networks use to signal things like geographic origin or peering policy. While perfect for debugging today’s Internet, this approach lacks historical context; you can’t telnet into 2012 to check a routing table from 14 years ago.
Subscribe to a Stream
For real-time views, services like RIPE RIS Live aggregate BGP data from global collectors and stream it over a public WebSocket. You can watch the Internet “breathe” as routes are announced and withdrawn thousands of times per second. This is fascinating for a live dashboard, but useless for backfilling history.
Here’s an example script consuming this stream:go/stream_bgp/main.go (click to expand)View on GitHub
package main
import (
"fmt"
"log"
"os"
"os/signal"
"time"
"github.com/gorilla/websocket"
)
// RIPE RIS Live WebSocket URL
const risLiveURL = "wss://ris-live.ripe.net/v1/ws/?client=kmcd-internet-map"
// Message defines the structure of the JSON messages we receive
type Message struct {
Type string `json:"type"`
Data map[string]interface{} `json:"data"`
}
func main() {
// Handle Ctrl+C gracefully
interrupt := make(chan os.Signal, 1)
signal.Notify(interrupt, os.Interrupt)
fmt.Printf("Connecting to %s...\n", risLiveURL)
c, _, err := websocket.DefaultDialer.Dial(risLiveURL, nil)
if err != nil {
log.Fatal("dial:", err)
}
defer c.Close()
// Subscribe to the firehose (all messages)
// You can filter this! e.g., {"host": "rrc21"} for a specific collector
subscribeMsg := map[string]interface{}{
"type": "ris_subscribe",
"data": map[string]interface{}{
"moreSpecific": true,
"type": "UPDATE", // Only show route updates
},
}
if err := c.WriteJSON(subscribeMsg); err != nil {
log.Fatal("subscribe:", err)
}
fmt.Println("Connected! Streaming global BGP updates...")
fmt.Println("------------------------------------------------")
done := make(chan struct{})
go func() {
defer close(done)
for {
var msg Message
err := c.ReadJSON(&msg)
if err != nil {
log.Println("read:", err)
return
}
// We only care about BGP UPDATE messages
if msg.Type == "ris_message" {
path := msg.Data["path"]
prefix := msg.Data["announcements"]
// Handle withdrawals (routes being removed)
if prefix == nil {
prefix = "WITHDRAWAL"
}
// Print the timestamp, the route prefix, and the AS path
fmt.Printf("[%s] Prefix: %v | Path: %v\n",
time.Now().Format("15:04:05"),
prefix,
path,
)
}
}
}()
// Wait for interrupt
<-interrupt
fmt.Println("\nDisconnecting...")
err = c.WriteMessage(websocket.CloseMessage, websocket.FormatCloseMessage(websocket.CloseNormalClosure, ""))
if err != nil {
log.Println("write close:", err)
return
}
select {
case <-done:
case <-time.After(time.Second):
}
}
The output looks like this:Websocket Stream Output (click to expand)View on GitHub
Connecting to wss://ris-live.ripe.net/v1/ws/?client=kmcd-internet-map...
Connected! Streaming global BGP updates...
------------------------------------------------
[22:52:35] Prefix: [map[next_hop:2001:7f8:24::b1 prefixes:[2804:70c0::/32]]] | Path: [58057 6939 22381 1031 263444 22381 270746]
[22:52:35] Prefix: [map[next_hop:2001:7f8:24::aa,fe80::8a7e:25ff:fed3:420b prefixes:[2a13:9404::/32]]] | Path: [6939 215120 34689]
[22:52:35] Prefix: [map[next_hop:2001:7f8:24::aa,fe80::470:71ff:fec5:b6ad prefixes:[2a14:7c0:1740::/48 2a10:ccc7:b110::/44]]] | Path: [196621 6939 215120 214497 6204 215120 214497]
[22:52:35] Prefix: [map[next_hop:2001:7f8:24::aa,fe80::224:38ff:fea4:a907 prefixes:[2a14:7c0:1740::/48 2a10:ccc7:b110::/44]]] | Path: [29691 6939 215120 214497 6204 215120 214497]
[22:52:35] Prefix: [map[next_hop:91.206.52.177 prefixes:[2a10:ccc7:b110::/44 2a14:7c0:1740::/48]]] | Path: [58057 6939 215120 214497 6204 215120 214497]
[22:52:35] Prefix: [map[next_hop:2001:7f8:24::b1 prefixes:[2803:5d10::/32]]] | Path: [58057 6939 3356 28343 272053]
[22:52:35] Prefix: [map[next_hop:2001:7f8:24::aa,fe80::8a7e:25ff:fed3:420b prefixes:[2a14:7c0:1740::/48 2a10:ccc7:b110::/44]]] | Path: [6939 215120 214497]
[22:52:35] Prefix: [map[next_hop:2001:7f8:24::aa,fe80::470:71ff:fec5:b6ad prefixes:[2a13:9404::/32]]] | Path: [196621 6939 215120 34689]
2026/02/09 22:52:35 read: websocket: close 1000 (normal)
Download Historical Snapshots
To build the historical model, I processed raw RIB (Routing Information Base) files. These are snapshots of the entire routing table as seen by a backbone router at a specific moment in time. Because BGP is a “chatter” protocol that only announces changes, these full table dumps are essential for reconstructing the state of the Internet at any point in the past.
I specifically fetched snapshots from February 1st at 12:00 UTC for every year in my timeline. To ensure a comprehensive view, I aggregated data from multiple global collectors maintained by the University of Oregon Route Views project.
Other excellent resources for this kind of data include:
- RIPE RIS (Routing Information Service): Provides high-fidelity snapshots from a dense network of collectors, primarily in Europe.
- CAIDA BGP Stream: A framework for analyzing both real-time and historical data from various sources.
How BGP Shapes the Global Internet Map
For this edition, I processed over 15 years of BGP snapshots and PeeringDB archives to build the Logical Dominance model. Reconstructing this history was easily the hardest part of the project. I quickly realized that reliable archival data for physical peering effectively vanishes before 2010, which set a hard limit on how far back I could take the timeline.
Defining Logical Dominance
Logical Dominance is calculated by summing the number of unique IPv4 addresses originated by an ASN and attributed to a given city. Overlapping prefixes are deduplicated using longest-prefix normalization so that no address space is counted twice.
The Scaling Problem: Why not IPv6?
You might notice this model focuses entirely on IPv4. While IPv6 is the future of the protocol, its sheer scale currently breaks the “Logical Dominance” math. I measure dominance by counting unique IP addresses; if I treated IPv4 and IPv6 as equals, the numbers wouldn’t just be skewed; they’d be nonsensical.
Consider the math: The smallest standard IPv6 assignment is a /64. That single subnet contains 18,446,744,073,709,551,616 addresses. You could fit the entire global IPv4 routing table (4,294,967,296 addresses) inside that one subnet 4.3 billion times over.
If I treated every IP equally, a single residential IPv6 connection would statistically obliterate a city hosting the entire legacy IPv4 Internet. Until I develop a weighted model for IPv6, perhaps based on prefix density rather than raw address count, IPv4 remains the only way to compare global “weight” on a 1:1 scale.
Finding the Truth in the Noise
Mapping a BGP prefix to a specific city is more difficult than you may think. A subnet might be registered to a corporate HQ but serve users thousands of miles away. To solve this, I built a prioritized “waterfall” of attribution logic. I check sources in order of reliability, stopping as soon as I find a match:
- Geofeeds (RFC 8805): These are machine-readable CSVs where network operators explicitly self-report where their subnets are used.
- Cloud Provider Ranges: I ingest live IP lists from AWS, Google Cloud, and others, mapping logical regions (like
eu-west-1) to their physical locations (Dublin). - Network Hints (Communities & Next-Hops): At this point, I look to the routing table itself for hints. If a prefix is only announced at the London Internet Exchange, or tagged with a “London” BGP Community, I attribute it there.
- Historical WHOIS: My final fallback for specific location data is the APNIC/RIPE databases.
- Footprint Heuristic: For anything remaining, I assign the IP weight to every city where that network maintains physical peering capacity as listed in PeeringDB.
This approach ensures that accurate, granular data (like a specific cloud region) always overrides broad, administrative data (like a generic WHOIS entry).
Building this pipeline presented unique engineering hurdles; here are the most significant ones:
The Local Cache
Downloading 15 years of archives is slow. I threw together a quick file-based cache to avoid hitting the network repeatedly. It was the simplest code I wrote but easily the most valuable, turning 30-minute download waits into near-instant local reads.
RAM remains stubbornly finite
Loading millions of IP prefixes, WHOIS records, PeeringDB entries, and their associated metadata into a standard in-memory map consumes gigabytes of RAM instantly. Frustratingly, my laptop only has so much. To avoid out-of-memory errors I built a custom on-disk trie data structure using BadgerDB v4, which is a Go KV store built on an LSM tree, which makes IP prefix lookups very efficient. I might show it off in a later blog post after I clean it up a little bit. By using IP prefixes as keys in a sorted KV store, I can perform efficient longest-prefix matching directly against the disk.
Cleaning Up the Spaghetti
While investigating all of these different data sources, I ended up writing several programs that generated output of different shapes that would be used by other programs. It all made sense to me at the time but it spiraled out of control into a confusing mess. Now, I have one script for generating this city data. I was only able to do this because of the improvements mentioned above: caching and using on-disk data structures. Now, the script has clear stages of:
- Fetch: Downloads and caches raw data (WHOIS, BGP, PeeringDB).
- Index: Builds searchable on-disk tries and resolves authoritative network names from RIRs.
- Process: Scans BGP routes and attributes each prefix using the various data sources mentioned above.
- Output: Produces clean, normalized city results without duplicate entries (e.g., merging “Seoul” and “SEOUL”).
What Changed When IP Dominance Was Added
When I layered IP dominance onto the physical map, many additional cities became visible.


In earlier versions, visibility depended heavily on registered Internet Exchange Points. That highlighted the traditional coastal hubs and major peering metros. But once routing table data was incorporated, the map revealed cities without major IXPs. These are places with substantial address space and large originating networks, even if they do not host a major public exchange. This is most noticeable in India, Japan, China, Indonesia, and in secondary metros beyond traditional hubs in the EU and United States.


The physical meeting points of networks only tell us a part of the story. The global routing table reveals where address space is actually controlled and originated. Some cities carry significant weight without being major public peering hubs. The IP dominance layer makes that distinction visible.


The Chinese Internet
The Chinese internet is giant, but it presents a unique attribution challenge. Because so much of China’s domestic routing remains internal to national carriers, the global BGP table often only sees these massive networks when they peer at international hubs like Hong Kong, Los Angeles, or Frankfurt. An earlier version of my attribution code ended up adding all of China’s IP space to these select few international hubs, which was clearly incorrect. It looked like China Telecom was the biggest ISP in Germany, which made it appear that China Telecom dominated Germany. It does not, at least not yet. To fix this, I implemented specific logic for China-based networks. I used pattern matching to parse provincial hints from APNIC WHOIS data. This mapped prefixes like GD or SH to their respective provincial capitals. I also linked ASNs to their parent organizations in PeeringDB to prevent Chinese networks from being misattributed to foreign exchange points. This resolved attribution for the vast majority of prefixes. Any remaining IP space attributed only at the country level is distributed across major domestic hubs.
The result is a far more realistic view of China’s internal internet topology.
Ghost Networks and Spurious ASNs
Not every entry in the global routing table represents a real network with a physical footprint. While investigating the data, I found several “spurious” Autonomous Systems that I had to filter out to keep the map accurate.
For example, I had to add safety checks to prevent “IP swallowing.” There is a massive 0.0.0.0/0 block often pinned to Australia in the APNIC database. Since 0.0.0.0/0 matches every single IPv4 address, that one entry would incorrectly claim the entire global IP space for Australia. I know they have a lot of open space down there, but that seemed excessive.
Another prominent example was the Department of Defense (DoD). The DoD holds several massive /8 blocks (like 7.0.0.0/8 and 11.0.0.0/8). While this space is technically routed, it does not represent commercial internet traffic. In early versions of my model, the registration data for these blocks linked them to administrative offices in New York City. This caused my script to dump millions of military IPs onto Manhattan and incorrectly made it look like the absolute center of the universe.
I also built a blocklist to ignore other non-geographic entities:
- Administrative Containers: I filter out WHOIS entries containing
IANA-NETBLOCK,CIDR-BLOCK, orERX-NETBLOCK. These are typically placeholders for unassigned pools managed by regional registries rather than active networks. - Registry Placeholders: Specific ASNs like 721, 56, and 37069 often function as loopbacks or registry tests.
By explicitly ignoring these, the resulting map represents the actual commercial Internet rather than the administrative database of the Internet.
UX and Rendering
In addition to adding more data to the map, I’ve also made several improvements to the map itself.
Dynamic Cluster Grouping
Layering BGP data onto an already complex physical map created a major design challenge: information density. With hundreds of new cities “lighting up” globally, the map became significantly cluttered when zoomed out.
To solve this, I implemented Dynamic Cluster Grouping. Close-by cities now group together into aggregate hubs at low zoom levels, which then split into individual markers as you zoom in. This isn’t just a visual fix; by reducing the number of active SVG shapes in the DOM, it significantly improves panning performance on mobile devices.
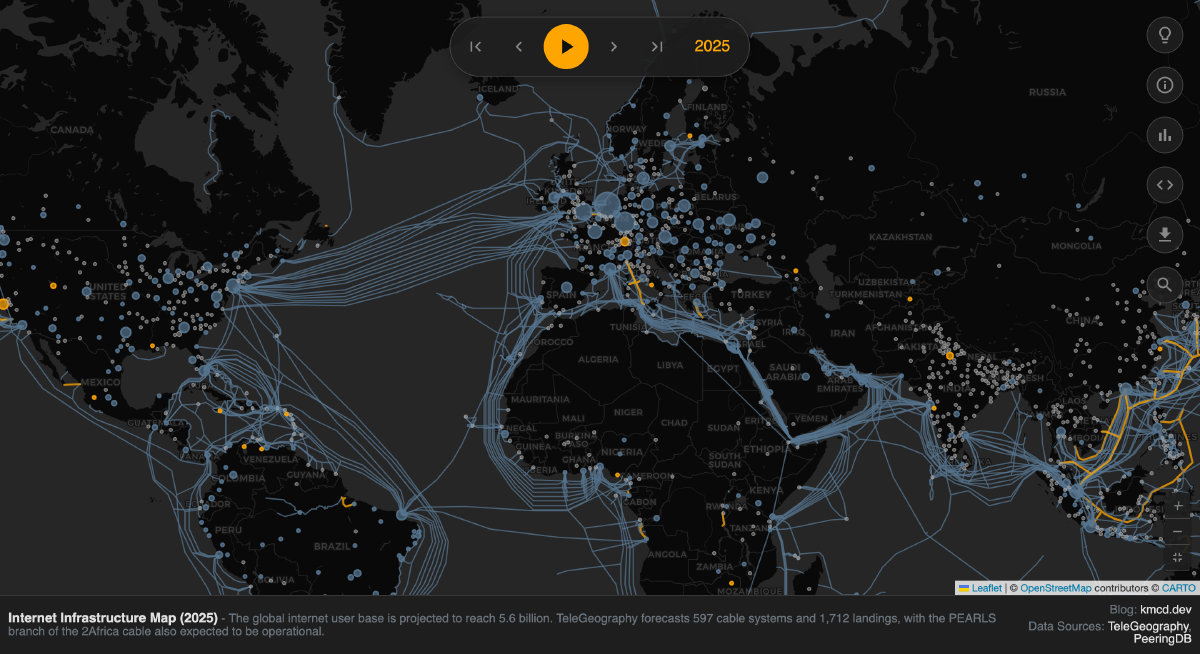
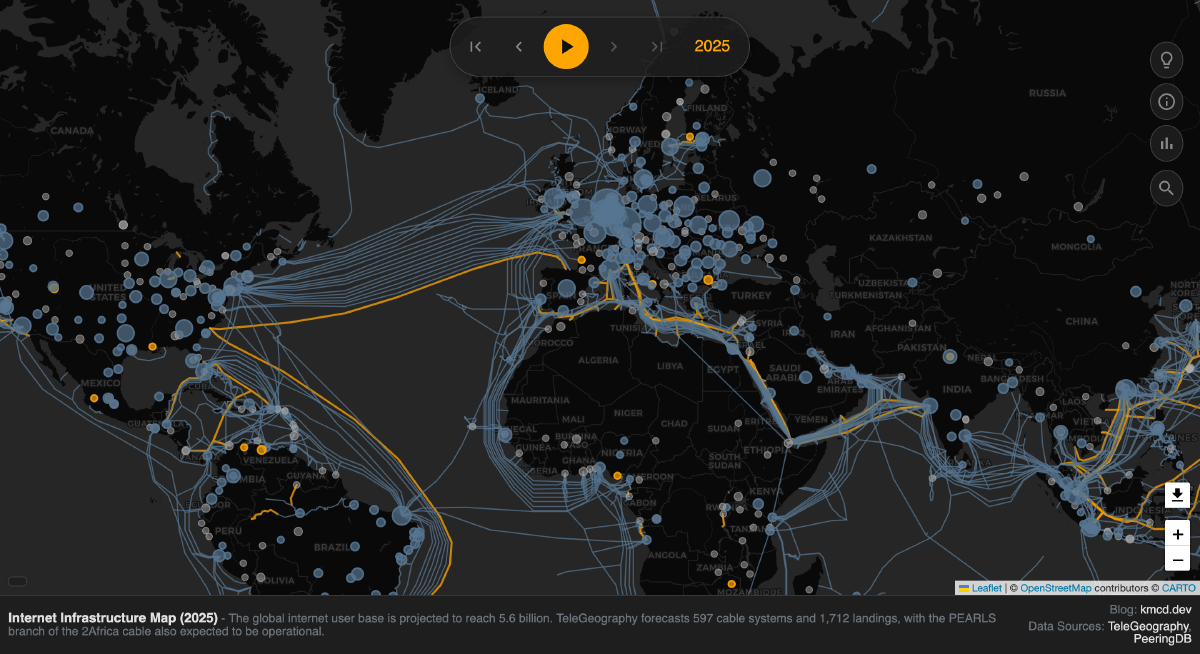
Dynamic Cluster Grouping ensures the map remains legible, preventing the increased data density from overwhelming the map. When you click on a cluster, the details panel expands to list every city contained within that group.
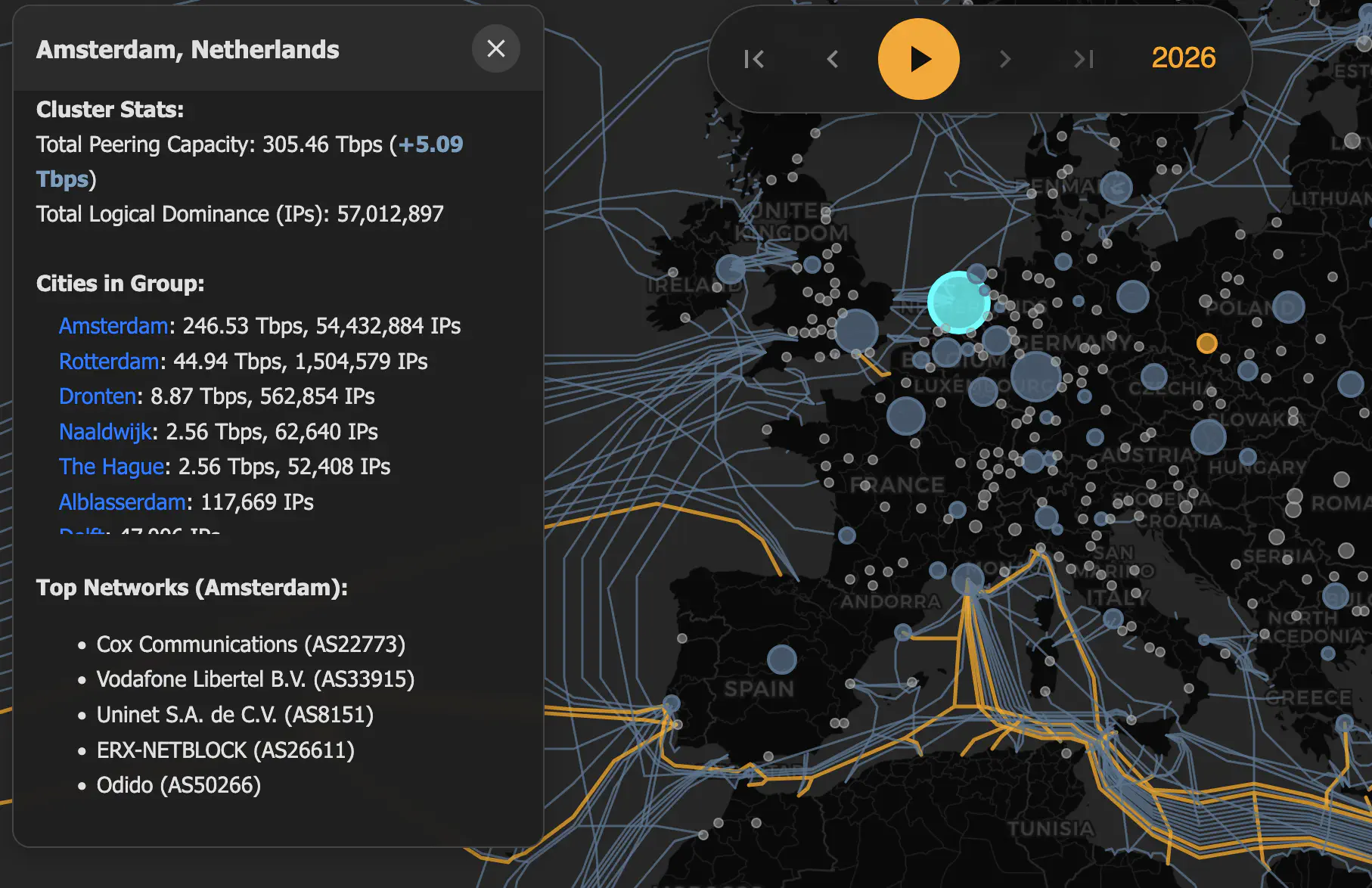
Viewport Culling
I also introduced Viewport Culling. The map now only renders assets currently within your bounds. As you pan to a new region, cities “pop in” dynamically, ensuring the browser isn’t wasting resources on rendering things on the other side of the planet.
Updates to City Sizing
The visual size of cities on the map also now dynamically reflects their importance. Previously, cities were sized based only on their relative peering bandwidth. Now, their size depends on a weighted combination of aggregate peering bandwidth and IP dominance, contributing 80% and 20% to the size calculation respectively. Although this ratio is arbitrary and was picked for aesthetic reasons, peering bandwidth is a stronger signal of real traffic concentration than raw IP space alone, so I think it should be emphasized significantly more.
Enable/disable layers
Now, the map can be sliced into three layers: Cables, peering bandwidth, and IP allocations. There are controls that allow you to show or hide each of these layers individually.

Permalinks
I also added permalinks to make the map state fully shareable. The URL now encodes the current latitude, longitude, zoom level, selected year, and active text filters. If you zoom into Southeast Asia in 2016 and search for “Singapore”, that exact view can be copied and shared. The resulting link will look like this:
https://map.kmcd.dev/?lat=3.1625&lng=103.4033&z=5.00&year=2016&q=singapore
…which will show exactly how amazingly connected Singapore is when others click on it.
Better Exports
One of the most requested features for the map has been a way to export the current view for use in presentations, reports, posters, or just as a high-quality wallpaper.
Previously, I was using a standard Leaflet plugin for this, but it was not great. It would often fail in weird ways, leaving you with a glitched or incomplete rendering of the map. It also exported as PNG, which meant the beautiful vector data of the cables and cities was flattened into a low-resolution raster format.
Now there’s a new export button that renders an isolated SVG. Because the map itself is built on SVGs, this new export method is lossless. It respects your current zoom level and position, allowing you to focus on a specific region and generate an incredibly high-quality vector file that you can scale to any size without losing a single pixel of detail. Most images in this post were generated using this new export feature.
Show Me the Data
Another one of the biggest requests I’ve had in previous years is for access to the raw data behind the visualizations. For the 2026 edition, I have exposed the underlying JSON datasets that power the map. These files are curated from TeleGeography (for modern cables), PeeringDB (for IXPs), and historical data is curated from various sources including submarinenetworks.com and archived maps.
You can access these directly to build your own visualizations, analyze the growth of global bandwidth, or double check my numbers.
all_cables.json: The Core Map Data. A GeoJSON FeatureCollection containing all submarine cables. Each feature includes properties likename,rfs_year(Ready for Service),decommission_year,owners, andlanding_points. This follows the standard GeoJSON format.year-summaries.json: Brief textual descriptions of notable events or milestones for specific years, displayed in the footer.city-dominance/{year}.json: Per-year JSON files (e.g., 2026.json) with detailed city-level peering capacity, regional information, and coordinates. Used for rendering city markers and calculating regional statistics.meta.json: Metadata including the minimum and maximum years covered by the visualization.
See You Next Year
You might ask why I burned so much time manually attributing IP space when services like MaxMind or IPInfo already exist. The honest answer? Buying the data isn’t fun. The joy of this project comes from the archaeology and the work involved in bringing order to chaotic and disjointed datasets and transforming them into something beautiful.
This was a great project, and I am extremely happy with the results. If you’ve gotten this far without checking out the map, I’m impressed with your restraint, but here’s one more link for you to take a look: Explore the Map »
Introduction
Welcome to the first installment of our “HTTP from Scratch” blog series! In this series, we’ll embark on a journey through the evolution of the Hypertext Transfer Protocol (HTTP), the backbone of the World Wide Web. By building simple implementations of each major HTTP version in Go, we’ll gain a deep understanding of how this essential protocol has shaped the internet we use every day and how it has evolved to what we have now. Be warned that none of the code will be the most performant, secure or featureful.
In this post, we’ll travel back to the early days of the web (1991) and explore HTTP/0.9, HTTP’s initial incarnation. At the time, HTTP/0.9 was a groundbreaking technology that enabled the first web browsers and servers to communicate, laying the foundation for the World Wide Web that we know today. But HTTP/0.9 had its limitations. We’ll discuss these shortcomings, which ultimately paved the way for subsequent versions of HTTP that introduced features like headers, status codes, and support for additional HTTP methods, connection reuse, binary framing and, eventually, abandoning TCP for UDP for better reliability and performance. For a more formal description of the HTTP/0.9 specification, you can reference http.dev or w3.org.
To get a hands-on understanding of HTTP/0.9, we’ll take a practical approach. Since no modern web servers support this early version, we’ll create our own HTTP/0.9 server from scratch using Go. This will allow us to experiment with the protocol and gain valuable insights into its inner workings.
By the end of this post, you’ll have a solid grasp of HTTP/0.9 and the foundation it laid for the modern web. You will be well-equipped to continue our journey through the evolution of HTTP in the upcoming articles.
Understanding HTTP/0.9
HTTP/0.9, the inaugural version of the Hypertext Transfer Protocol, laid the groundwork for the web as we know it today. It introduced a simple request-response model that facilitated communication between web clients and servers.
The Request
In HTTP/0.9, a client sends a single-line request to the server. This request line consists of only two components:
- GET Method: The only method supported in HTTP/0.9. It instructs the server to retrieve the specified resource.
- Resource Path: The path to the resource on the server that the client wants to access.
For example, to request the index.html file from the server’s root directory, the client would send:
GET /index.html
That’s… it. It can’t get much simpler than that. Note that there are no headers to indicate content size, compression, content type, etc. This isn’t a part of HTTP/0.9 as all of that was introduced in HTTP/1.0.
The Response
Upon receiving a request, the server responds with the contents of the requested resource. This response is a simple stream of bytes, usually representing an HTML document. Notably, there are no headers in an HTTP/0.9 response or a status code that tells us if we’re receiving an error page or the resource that we asked for. Since there were no status codes, there was no way to indicate if a requested resource was not found — a concept that would later be introduced with the 404 status code.
Full example
> GET /index.html
< <html>
< Hello World!
< </html>
Again, this is an extremely simple protocol at this point. Request a resource and get the data. There’s no place to put metadata when requesting or responding. By the way, lines prefixed with > are from the client to the server and < are from the server to the client. Remember this, because this is important for understanding verbose curl output, which we’ll use a good amount in the future.
sequenceDiagram
actor Client
rect rgb(47,75,124)
Client ->> Server: TCP SYN
Server ->> Client: TCP SYN-ACK
Client ->> Server: TCP ACK
end
rect rgb(200,80,96)
Client ->> Server: HTTP Request
Server ->> Client: HTTP Response
end
rect rgb(47,75,124)
Server ->> Client: TCP FIN
Client ->> Server: TCP ACK
end
Limitations
While revolutionary for its time, HTTP/0.9 had some significant limitations that paved the way for future improvements:
- No Headers: The absence of headers meant that the server could not convey any additional information about the response, such as content type or length.
- Only GET: The only supported method was GET, which meant that clients could only request resources and not submit data to the server.
- No Status Codes: There was no mechanism to indicate errors or other status information.
Implementing an HTTP/0.9 Server
Okay, now let’s implement the server.
type Server struct {
Addr string
Handler http.Handler
}
func (s *Server) ListenAndServe() error {
if s.Handler == nil {
panic("http server started without a handler")
}
l, err := net.Listen("tcp", s.Addr)
if err != nil {
return err
}
defer l.Close()
for {
conn, err := l.Accept()
if err != nil {
log.Fatal(err)
}
go s.handleConnection(conn)
}
}
You can see here that our ListenAndServe() listens on the configured TCP port and then loops forever, accepting and handling new connections in separate goroutines. Now let’s look at s.handleConnection()
func (s *Server) handleConnection(conn net.Conn) {
defer conn.Close()
reader := bufio.NewReader(conn)
line, _, err := reader.ReadLine()
if err != nil {
return
}
fields := strings.Fields(string(line))
if len(fields) < 2 {
return
}
r := &http.Request{
Method: fields[0],
URL: &url.URL{Scheme: "http", Path: fields[1]},
Proto: "HTTP/0.9",
ProtoMajor: 0,
ProtoMinor: 9,
RemoteAddr: conn.RemoteAddr().String(),
}
s.Handler.ServeHTTP(newWriter(conn), r)
}
Handling a connection is very simple in HTTP/0.9 because clients can only create a new connection, send a single request and then the connection is closed. This code reads the first line given by the user and then calls strings.Fields to split the different parts of the request up. As a reminder, this is what the request looks like in HTTP/0.9:
GET /path/to/resource
Okay, now let’s look at what newWriter does. ServeHTTP expects a http.ResponseWriter, which looks like this:
type ResponseWriter interface {
Header() Header
Write([]byte) (int, error)
WriteHeader(statusCode int)
}
Here’s what our HTTP/0.9 looks like:
type responseBodyWriter struct {
conn net.Conn
}
func (r *responseBodyWriter) Header() http.Header {
// unsupported with HTTP/0.9
return nil
}
func (r *responseBodyWriter) Write(b []byte) (int, error) {
return r.conn.Write(b)
}
func (r *responseBodyWriter) WriteHeader(statusCode int) {
// unsupported with HTTP/0.9
}
func newWriter(c net.Conn) http.ResponseWriter {
return &responseBodyWriter{
conn: c,
}
}
The important thing to note here is that HTTP/0.9 doesn’t support status codes or headers so we don’t need to do anything in Header() and WriteHeader(statusCode)
Now let’s put it together in a main function:
func main() {
addr := "127.0.0.1:9000"
s := Server{
Addr: addr,
Handler: http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("Hello World!"))
}),
}
log.Printf("Listening on %s", addr)
if err := s.ListenAndServe(); err != nil {
log.Fatal(err)
}
}
Note that the HTTP handler is a normal-looking http.Handler so this server could work with any existing HTTP router or framework.
See the full source at Github: main.go.
Testing the server
Now we just need to run the server:
$ go run server/main.go
2024/07/27 21:55:28 Listening on 127.0.0.1:9000
Now that we have an HTTP/0.9 server, how do we test it?? Since HTTP/0.9 pretty much isn’t used anywhere, how do find a client to test this server? Luckily, curl supports HTTP/0.9, so let’s try that!
$ curl --http0.9 http://127.0.0.1:9000/this/is/a/test
Hello World!
The –http0.9 flag instructs curl to accept the headerless responses of HTTP/0.9.
You should note that curl is sending a request as if it were HTTP/1.1 but is configured to accept the headerless responses of HTTP/0.9. Here’s what the curl manpage says about the flag:
--http0.9
(HTTP) Tells curl to be fine with HTTP version 0.9 response.
HTTP/0.9 is a completely headerless response and therefore you can also connect with this to non-HTTP servers and still get a response since curl will simply transparently downgrade - if allowed.
I verified this behavior a bit more when I mixed --http1.0 and --http0.9. Instead of using HTTP/1.1 in the first line of the request, curl declares that it is using HTTP/1.0 while still treating the body correctly (not expecting a status code or headers):
$ curl --http1.0 --http0.9 http://127.0.0.1:9000/this/is/a/test
Hello World!
By the way, if you don’t use the --http0.9 (or if your server returns the status code/headers in a format that doesn’t make sense) you will receive an error message, “Received HTTP/0.9 when not allowed”:
$ curl http://127.0.0.1:9000/this/is/a/test
curl: (1) Received HTTP/0.9 when not allowed
You can test this server with simpler tools. For example, netcat (ncat), can be used to make this same request. This will be a theme for the text-based protocols where often it’s simpler just to write text out directly to netcat than it is to use other kinds of tooling:
$ echo GET this/is/a/test | ncat 127.0.0.1 9000
Hello World!
After writing most of this article, I finally realized that I never even attempted to test my web server using a real web browser. It seems like the only major browser that still supports HTTP/0.9 is Firefox, so let’s see it!
Yes, it works! Success!
Implementing an HTTP/0.9 Client
Now that we’ve made a server and used existing clients, we might as well make a client in Go. Don’t worry, this one is super simple:
conn, err := net.Dial("tcp", "127.0.0.1:9000")
if err != nil {
log.Fatalf("err: %s", err)
}
if _, err := conn.Write([]byte("GET /this/is/a/test\r\n")); err != nil {
log.Fatalf("err: %s", err)
}
body, err := io.ReadAll(conn)
if err != nil {
log.Fatalf("err: %s", err)
}
fmt.Println(string(body))
See the full source at Github: main.go.
This code does the following:
- Establishes a TCP connection to the server.
- Sends the HTTP/0.9 request.
- Receives the response and displays it to the user.
Simple, right? Almost too simple.
$ go run client/main.go
Hello World!
Conclusion
In this post, we delved into the origins of the web by exploring HTTP/0.9. While simple in its design, HTTP/0.9 was a groundbreaking protocol that enabled the first web browsers and servers to communicate.
We explored the basic request-response model of HTTP/0.9, understanding how clients could request resources and servers could deliver them. We also acknowledged the limitations of this early version, including the lack of headers, status codes, and support for other HTTP methods besides GET.
By building a rudimentary HTTP/0.9 server and client in Go, we gained hands-on experience with the protocol’s core concepts. We learned how to handle TCP connections, parse requests, and send responses, laying a solid foundation for understanding more advanced HTTP versions.
In the upcoming parts of this series, we’ll delve into how HTTP evolved to overcome the limitations of HTTP/0.9 and address the needs of the evolving World Wide Web. We’ll explore the introduction of headers, status codes, and additional methods, which enabled more robust and feature-rich communication between web clients and servers. Stay tuned for the next part of our series, where we’ll dive into HTTP/1.0 and its significant enhancements over HTTP/0.9. As a sneak peek, these are the major features added to each version:
- HTTP/0.9: First attempt to transfer generic resources by paths
- HTTP/1.0: Adds status codes, headers, verbs
- HTTP/1.1: Adds connection re-use so connections can be reused
- HTTP/2: Switches from a text-based protocol to binary
- HTTP/3: Built on QUIC instead of TCP
Major Projects
protoc-gen-connect-openapi
A protoc plugin that generates OpenAPI 3 definitions from Connect and gRPC service definitions, enabling seamless integration with OpenAPI-based tools.
fauxrpc
A tool that generates fake gRPC and Connect servers based on your Protobuf definitions. It produces realistic, randomized data that adheres to your service's constraints.
ProtoDocs
A protobuf-first documentation browser for APIs that deserve better than ugly generated docs.
protobuf.kmcd.dev
An interactive playground for exploring Protocol Buffers, from schema design and validation to binary wire formats and serialization efficiency.
Internet Maps
A collection of projects visualizing and explaining the global routing and physical infrastructure of the Internet: map.kmcd.dev (cables & peering map), livemap.kmcd.dev (real-time routing updates stream), and bgp.kmcd.dev (interactive BGP explainer).