
This post is part of the gRPC: the good and the bad series.
gRPC has undeniably become a powerful tool in the world of microservices, offering efficiency and performance benefits, but gRPC also has an ugly side. As someone who’s spent a considerable amount of time with gRPC, I’d like to shed light on some of the uglier aspects of this technology. I’ve already talked about the good and bad parts of gRPC, now let’s talk about the ugly.
Generated Code
To get started, I have to talk about how ugly the code generated from protobuf definitions is. It has historically been verbose, complex, and difficult to navigate. Even though it’s not meant to be hand-edited, this can impact code readability and maintainability, especially when integrating gRPC into larger projects. This has actually improved a lot recently in most languages but even so, there are some rough edges.
Language-specific Quirks
Protobuf and gRPC’s initial implementations often diverged from language-specific norms, especially in their HTTP handling. This stemmed partly from the decision to mandate HTTP/2 support, a decision that has since proven to limit gRPC’s reach into the web frontend. We know now from gRPC-Web that trailers aren’t a hard requirement for a protocol like gRPC. In the aftermath of this decision, we are now left with a need to evolve the language implementations of protobuf and gRPC to be more idiomatic for each language.
For Go, avoiding the net/http package is a rough decision because it makes it harder to use gRPC endpoints alongside other kinds of HTTP APIs and to re-use HTTP middleware. They eventually added a ServeHTTP() interface to grpc-go as an experimental way to use the HTTP server from the Go standard library but using that method results in a significant loss of performance. Maybe they did it for performance reasons? If so, it’s definitely a tradeoff that has split gRPC from the rest of the Go ecosystem.
Sometimes language quirks actually impact how you design protobuf types. If you follow the style recommendations from Buf, the names of enums are expected to be prefixed an upper-snake-case version of the enum name, like so:
enum FooBar {
FOO_BAR_UNSPECIFIED = 0;
FOO_BAR_FIRST_VALUE = 1;
FOO_BAR_SECOND_VALUE = 2;
}
This is described better in the buf lint rule description for ENUM_VALUE_PREFIX but the style guide is like this because of C++ scoping rules with enums, which makes it impossible to have two enum values in the same package with the same enum value name. While this convention originated from C++ scoping rules, it affects how you should design all protobuf files. Why would scoping inside of the enum not be enough for the C++ compiler to generate unique names? Why is this flaw something that impacts the style guide and, in effect, all target languages? To me, this is kind of ugly, because quirks of some language implementations are bubbling up in unintuitive ways.
The generated code isn’t even that fast
One benefit of generated code is that you can generate code that no sane human would write in order to get some performance optimizations. However, if you look at some of the code generated from protobuf you’ll see runtime reflection used a lot. Why? In a way, I am saying the generated code isn’t ugly enough. Let’s look at a concrete example. Be warned that this will be a very Go-specific section because most of my experience with protobufs is in Go. However, the same strategy has been applied in most languages.
Let’s take a look at super a simple example in Go. Here’s the protobuf:
message Hello {
string name = 1;
}
Here’s the type generated by protoc:
type Hello struct {
state protoimpl.MessageState
sizeCache protoimpl.SizeCache
unknownFields protoimpl.UnknownFields
Name string `protobuf:"bytes,1,opt,name=name,proto3" json:"name,omitempty"`
}
// With these methods, contents are stripped
func (*Hello) Reset()
func (*Hello) String() string
func (*Hello) ProtoMessage()
func (*Hello) ProtoReflect() protoreflect.Message
There’s actually no Marshal() or Unmarshal() functions defined specifically for this type. This means that runtime reflection is used to make serialization work. Reflection is generally seen as slower, because it is slower. I find it strange that optimized, type-specific serialization code isn’t being generated for Go. That said, you can actually get this by using a separate protoc plugin called vtprotobuf that will generate specialized marshal and unmarshal functions for each protobuf type. It also allows for using type-specific memory pools, which can also help reduce allocations and improve performance. From my own testing just adding vtprotobuf with zero code changes can improve performance by 2-4%. This is essentially a “free” 2-4%, so it’s super strange to me that this wouldn’t be part of the standard compiler. You may not like it, but this is what peak performance looks like. Anyway, this project needs more love and support.
Note that there are other efforts which claim outrageous improvements over what the standard protobuf library does. They do make tradeoffs to achieve these performance gains, but many times the extra complexity is worth it.
You might have read this section and thought “well, this would increase the amount of code being generated and increase binary or package sizes and in some environments, you might not want that. That’s true amd that’s why protobuf has an optimize_for option, so you can annotate one of the following:
option optimize_for = SPEED;- more verbose, faster codeoption optimize_for = CODE_SIZE;- smaller codeoption optimize_for = LITE_RUNTIME;- intended to run on a smaller runtime that omits features like descriptors and reflection.
See the full description for optimize_for on the official protobuf documentation. While these options exist, they aren’t actually used for most target languages. In the future I would totally like to see most of vtprotobuf be rolled into the standard protobuf compiler for Go and be used if optimize_for = SPEED. Integrating vtprotobuf-like optimizations into the standard protobuf compiler could offer significant performance gains for Go and there are potentially similar opportunities in other languages as well.
Required Fields
The maintainers of protobuf learned some hard lessons with required fields. They felt like they misstepped so badly, that they made a new version of protobuf, proto3, just to remove required fields from the spec. Why? The author of the “Required considered harmful” manifesto talks about this in a lengthy hacker news comment, but the important bit is:
Real-world practice has also shown that quite often, fields that originally seemed to be “required” turn out to be optional over time, hence the “required considered harmful” manifesto. In practice, you want to declare all fields optional to give yourself maximum flexibility for change.
This is echoed by the official style guide of protobufs, where they recommend adding a comment indicating that a field is required. If we’re talking about getting a message from A to B, I totally agree with this line of thinking. However, just because the fields that are considered “required” change over time doesn’t mean required fields don’t exist. There still needs to be code that enforces this requirement and I’d rather not write this code, to be honest. Therefore, I think the best way of handling required fields without writing a bunch of null checks everywhere is by using protovalidate or a similar library that has protobuf options that allow you to annotate which fields are required. Then there is code on the server and/or client that can enforce these requirements using a library. In my opinion, this has the best of both worlds: you can still declare required fields in a way that doesn’t completely break message integrity.
I don’t like this:
message User {
int32 age = 1; // required.
}
I do like this:
message User {
int32 age = 1 [(buf.validate.field).required = true];
}
I’m a big fan of protovalidate and I’ve used it a good amount and have contributed to it. Generally, I think custom options for protobuf fields is an untapped superpower of protobufs.
Failure to Launch
While gRPC has undeniable advantages, its learning curve can be steep. Getting started with protobuf, understanding the tooling, and setting up the necessary infrastructure can be intimidating for newcomers, making the initial adoption hurdle higher than with simpler JSON-based APIs. Why is it steep? Well, it introduces non-idiomatic tooling to most languages. There are some examples of language support that make protobuf generation seamless. Grpc.Tools for .NET is one shining example, showing how protobuf tooling can be more integrated into standard language tooling. We need more of this.
The steep learning curve doesn’t help when many people who use and rely on protobuf and gRPC actively don’t want gRPC to extend to the frontend and think that pushing in this direction will lead to uninformed people encroaching on the domain of the backend, where only they are smart enough to work. This is elitist gate-keeping and is unfortunately prevalent in this industry. I believe gRPC has as much of a place in web frontends as much as it does in microservices.
I’ve learned a lot by helping others work with protobuf. You may see me on Buf’s slack channel or on related discussions because I truly have gotten a lot out of it. Many article ideas have come directly from answering questions there. If I see a problem often enough, I may end up writing an article about it. I believe the protobuf and gRPC community needs more of this attitude.
I believe the steep learning curve (which can be helped with tooling), coupled with some resistance from backend developers (which can be helped by… having empathy?), has slowed its broader adoption in web development.
gRPC Has a History
gRPC’s initial focus on microservices and its close ties to HTTP/2 hindered its widespread adoption in web development. Even with the advent of gRPC-Web, there’s still a perception that it’s not a first-class citizen in the frontend ecosystem. The lack of robust integration with popular frontend libraries like TanStack Query further solidifies this notion to me.

I think there’s a real chance to get more frontend developers excited about gRPC with improved tooling. There’s a giant industry-wide conversation happening right now around where the line between “frontend” and “backend” meet and I think no matter the outcome, we’re going to see more typescript code using gRPC.
The “g” in gRPC
While the gRPC project claims that the “g” in gRPC is a backronym that stands for “gRPC”, it originally stood for Google, because it was Google who developed and released both protobuf and gRPC.

There’s always a lingering question about Google’s long-term commitment to gRPC and protobuf. Will they continue to invest in these open-source projects, or could they pull the plug if priorities shift? Remember that Google has recently layed off much of the Flutter, Dart and Python teams. The protobuf community is growing, but would it be self-sustaining enough to survive such a scenario?
It’s Not Finished
Others have said that gRPC is immature, not because of its age but by how developed the ecosystem is. I tend to agree, because it’s missing features and tools that I would have expected from a mature ecosystem.
The missing package manager
Sharing protobuf definitions across multiple projects or repositories is a constant struggle without specialized tools. While solutions like Bazel, Pants, and Buf’s BSR exist, my experience with protobuf “in the real world” is… mixed. There are prominent open source projects, some by Google, that have bash scripts scrapped together to download dependencies before evoking protoc manually. Just imagine a programming language with no solution for managing dependencies. That’s insane. I think both Bazel and Buf tooling solve this problem pretty well but I’m just frustrated that every repo I come across that uses protobuf solves the problem in the most bespoke way possible. The community needs to come together to improve this. There is an open-source repo called Buffrs that appears to be tackling this problem. I haven’t used it personally but it looks decent so far.
Related to dependencies, I do want to call out that Google’s “well-known” protobuf types get special privilege of being built into protoc. While these types are incredibly useful and invaluable, their privilege makes it hard for other libraries of useful protobuf types to exist and thrive. Just building these protobuf definitions into protoc (and other tooling) is a cop out for not having a real and consistent story for dependency management.
Editor Support
Editor integration for protobuf code generation leaves a lot to be desired. It would be immensely helpful if editors could intelligently link generated code back to its protobuf source. This would provide a more seamless experience, but the tooling just isn’t smart enough yet. Also, I think everyone needs to run with Buf’s editor support. Having a linter and autoformatter built into your editor is the expected from developers nowadays. And with protobuf, there are extremely real reasons to follow the advice of the linter.
Projects like tRPC showcase the benefits of tight integration and opinionated design choices—something that protobuf, by its nature, can’t fully replicate. However, I remain hopeful that the protobuf ecosystem can evolve to offer a similarly streamlined developer experience.
Ugly Documentation
I’ve never seen documentation generated from protobuf that wasn’t super ugly. I think since gRPC has historically been a backend service, the backend devs never bothered to put any real effort into making pretty documentation output using a protoc plugin. I’ve solved this problem by making a protoc plugin that generates OpenAPI from given protobuf files. Then I use one of the many beautiful tools for displaying the OpenAPI spec. This was, by far, much easier than getting me to make a decent design. Another side benefit for generating OpenAPI from protobuf is the ability to tap into that ecosystem since there’s more to it than just documentation.
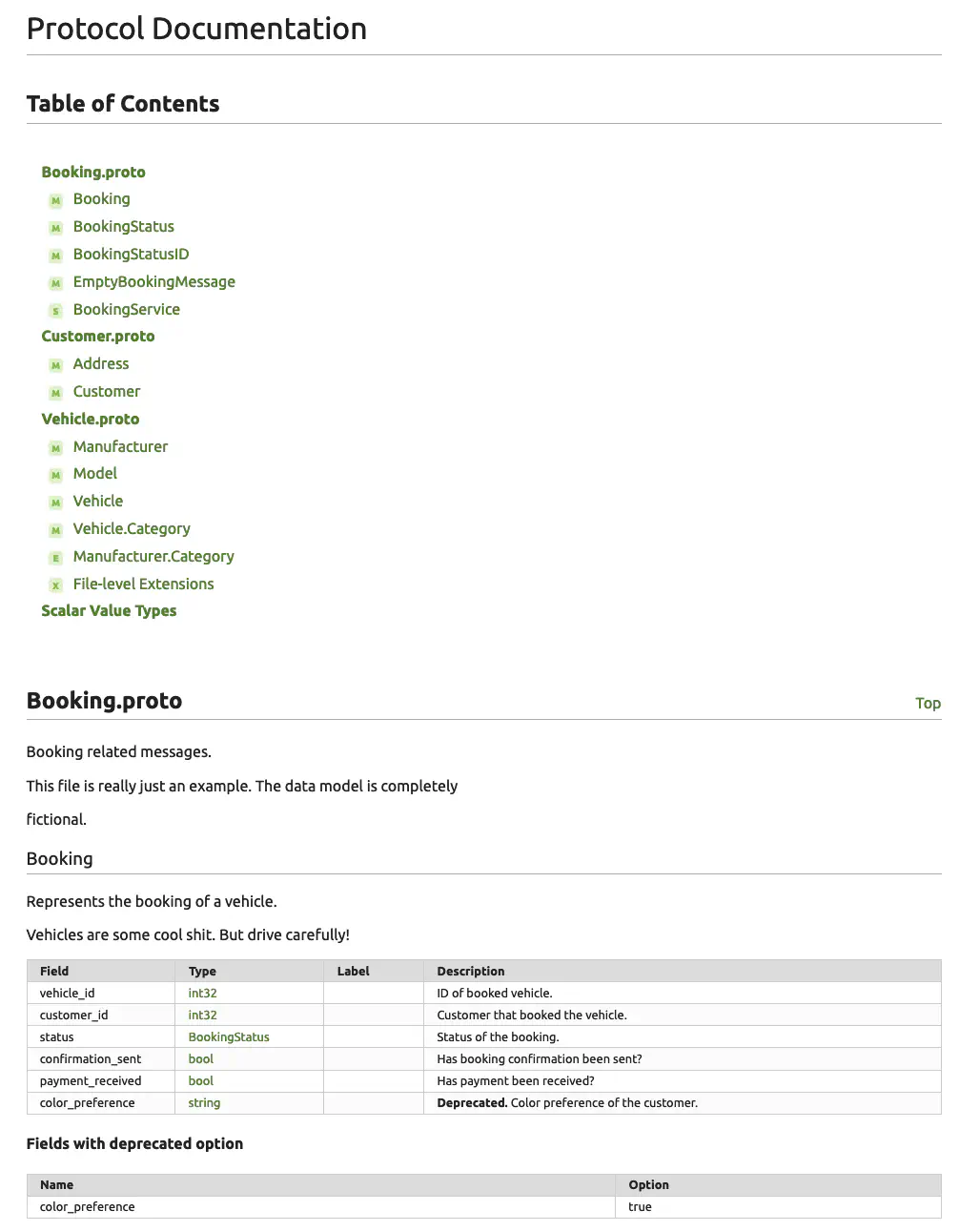
Let’s look at a real example. This is a document generated using one of the few tools for generating documentation from protobuf, protoc-gen-doc:
Compare it to some of the OpenAPI tooling. This was generated using Elements, but there are many, many other alternatives that look equally as polished:
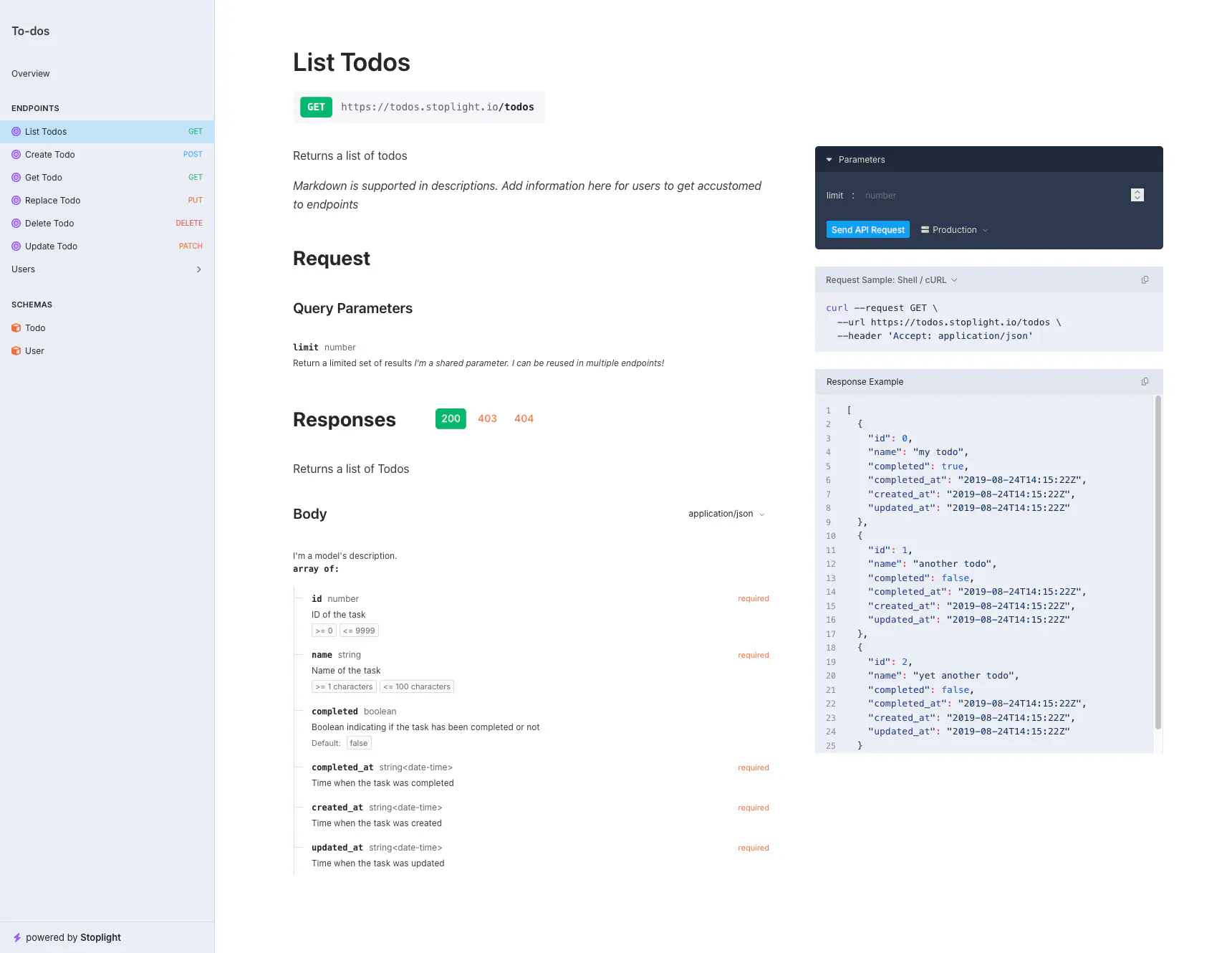
It’s kind-of not fair to point at a single plugin and say that the default template doesn’t look as good as OpenAPI alternatives, because you actually do have more flexibility with protoc-gen-doc. It allows you to specify your own template so it could look as beautiful as you want. However, this does line up with my point: the tooling is more finished and polished in the REST world than gRPC. This is a fixable problem, but we need to get frontend devs and designers excited about gRPC or backend engineers need to start sharpening their design skills.
I also want to note that OpenAPI/Swagger interfaces often have a way to test endpoints directly from the documentation website. This is completely missing from equivalent tools in the gRPC world. Additionally, with most OpenAPI documentation tools you can clearly see which fields are required and will display constraints on fields that have them. So not only is it prettier, it’s more functional as well.
Conclusion
gRPC, while a powerful tool in many ways, still has room to grow. The less-than-ideal aspects of generated code, coupled with the challenges of dependency management and evolving protobuf schemas, can create friction for developers. The lack of intuitive editor integration and the historical focus on backend services have also hindered its wider adoption in web development.
However, I think the future of gRPC is bright and can be far less ugly. The community is actively addressing these challenges, developing tools like the buf CLI, protovalidate and protoc-gen-connect-openapi to bridge the gaps and enhance the developer experience. As gRPC matures and its ecosystem expands, we can anticipate improved tooling, better editor support, and a smoother integration into the frontend world.
Share this post
Continue the series: gRPC: the good and the bad
- gRPC: The Bad Parts
- gRPC: The Good Parts
- gRPC: The Ugly Parts