I made a daily word game
Ever stare at a word so long it stops looking like a word? Like naming a variable data for the 8th time and suddenly wondering what data even means?
That effect is called semantic satiation. I made a game that dives headfirst into the theme.
In wordseq, you swap letters to form words, but the deeper you go, the more the grid feels like a linguistic fever dream. One moment you’re proud to find “plop”, the next you’re doubting if “plop” was ever a real word or just a sound effect from a comic book. You win by dragging yourself back to meaning. Enjoy the victory while you can, because there’s a new puzzle tomorrow.
I’m excited to share a look behind the scenes of my new daily word puzzle game, wordseq. If you haven’t tried it yet, you can play the latest puzzle here!. wordseq is a game where you swap adjacent letters to form new words, aiming to find the longest possible sequence. Here’s what it looks like to play the game (by a super unrealistically fast player).
One of the most challenging and rewarding aspects of building wordseq was developing the system that generates the daily puzzles. My goal was to create levels that are not just solvable, but also consistently engaging, fair, and offer that satisfying “aha!” moment where the answer you’ve been looking for hits you in the face. Conversely, I want to avoid the “Huh, is this actually the solution?” moments.
In this post, we’ll explore the intricate process of generating these daily puzzles. We’ll cover everything from initial grid creation and word validation to ensuring puzzles are solvable and use interesting vocabulary, leveraging techniques like concurrency in Go and smart dictionary management.

Core Gameplay Mechanics
Before we dive into generation, here’s a quick overview of how to play wordseq:
- The Core Mechanic: Players swap any two letters that are directly next to each other (horizontally or vertically).
- Word Formation: Each swap must result in at least one new word spanning the length of a row (this length can vary by difficulty). This new word is formed by the entire row or column where the swap occurred.
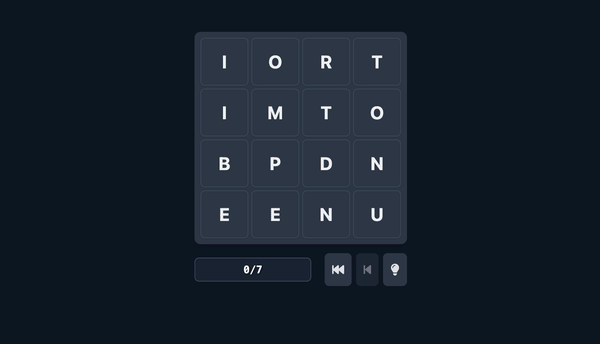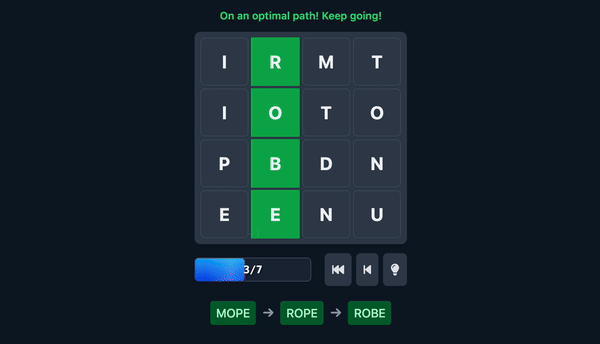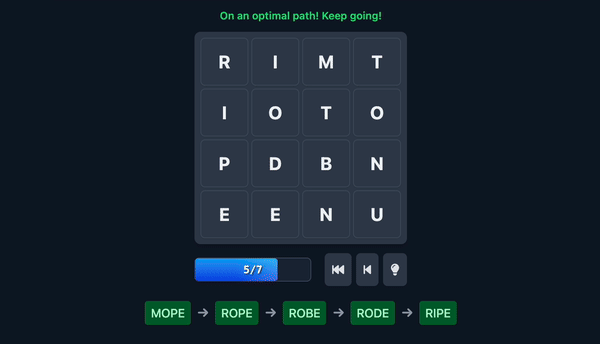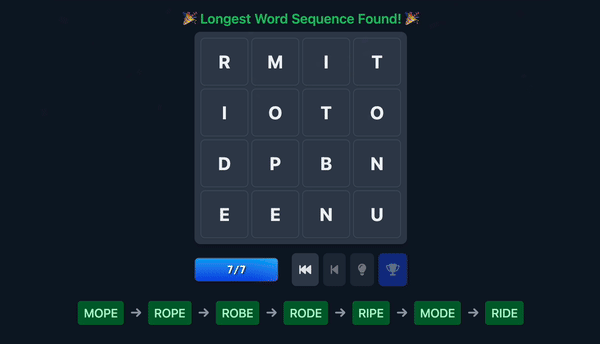
- The Goal: The objective is to find the longest possible sequence of valid words by making these swaps. This is what we call the “optimal path.”
- Difficulty Levels:
wordseqoffers ’normal’, ‘hard’, and ‘impossible’ modes, which influence parameters like grid size, word length, and the complexity of the solution paths the generator aims for.
To better understand how these swaps lead to word formation, let’s look at the visual feedback provided to the player during gameplay.
Movement
Here is what the movement looks like.
Bad move, results in no new words. Don’t you like the little wiggle? It’s the small things that really shape the experience:

Non-optimal move, a move that sets you up to fail. You may think that you made a clever move and discovered a word just slightly askew, but there are many times where there’s another word that you need to find first to best set up the longest sequence. You will be greeted by a not-as-scary orange color. Usually you will want to undo your move and look for another:

And, of course, the optimal move, the move that finds a new word but also sets you up for the most followup words.
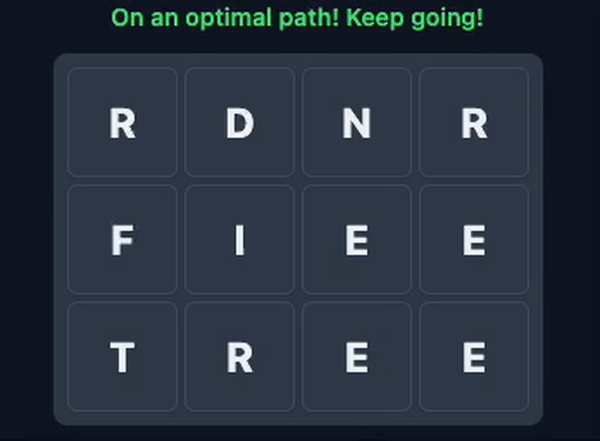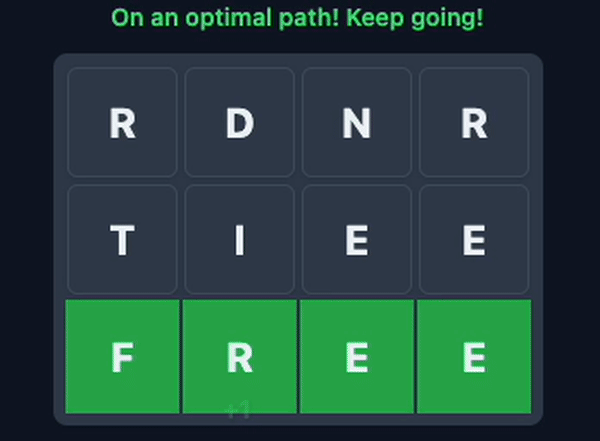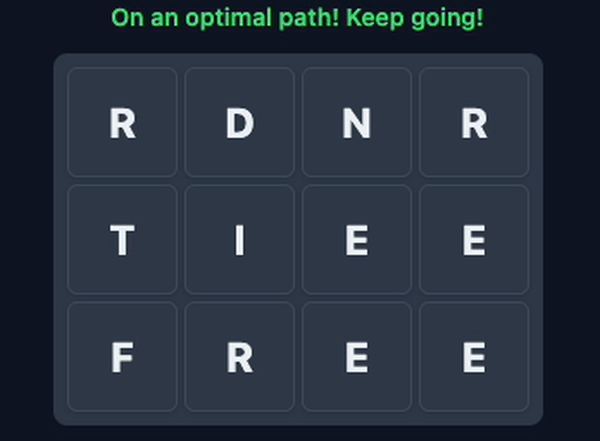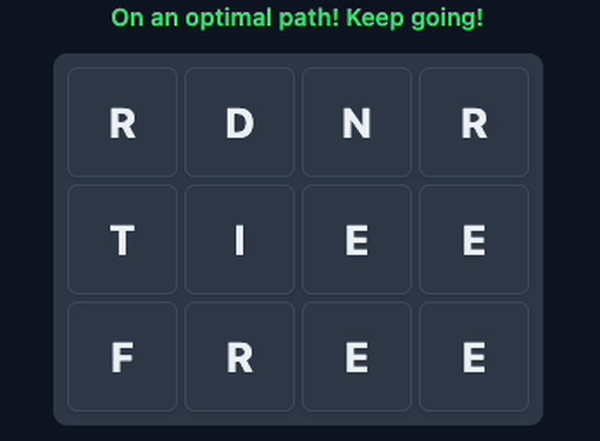
The challenge with this game isn’t only finding/completing words, but also setting yourself up for the next one. Don’t worry, there’s no downside for finding the ‘wrong’ paths.
The Tech Stack
The level generation is a computationally intensive process, so I opted to build the generation script in Go, primarily for its excellent performance and built-in support for concurrency, but also it’s the language that I know best right now. This script outputs JSON data for each level. There will be more on the level format later.
The frontend, where you play wordseq, is built with:
- React (using Vite for a fast development experience)
- TypeScript for type safety
- Tailwind CSS for styling
The JSON level data from the Go script is fetched by the React frontend to power each day’s puzzle.
Generating Engaging Levels
Crafting a “good” wordseq puzzle involves several steps and considerations. We want puzzles that aren’t too easy, don’t rely on super obscure words, and have a satisfying solution depth. Here’s how the generator tackles this:
Step 1: Initial Grid Generation
It starts with Randomness: The process starts by generating a grid (e.g., 5x5) filled with random letters. However, just picking letters completely at random can lead to grids full of very rare letters (like Q, Z, X, J) which makes forming words difficult or leads to trivial “write-offs” where those letters are ignored. To combat this, the generator uses approximate letter frequency (based on English language letter usage) to populate the grid. This creates a more balanced and natural distribution of letters, similar to what you might find in a Scrabble bag.
Initial Validation: Before any moves are possible, the generator verifies that the starting grid contains no valid words matching the puzzle’s target length. This ensures the puzzle begins only with the player’s first action and avoids potential confusion where the initial state might seem like part of the solution, or where swapping back to the original layout could be misinterpreted as finding a word.
This check involves looking for rows in each row and column, like this:

It is important to note that words spent going upwards and to the left aren’t seen as words. The game would be far too complex if that were the case.
Step 2: Building the Exploration Tree - Finding All Possibilities
This is where the magic (and a lot of computation) happens. For a given initial grid that passes validation, the generator explores all possible valid game sequences:
- Iteration: From the current grid state, it identifies every possible adjacent letter swap.

- Validating Swaps (The Big Dictionary): For each potential swap, it temporarily performs the swap and then checks if the new grid configuration forms at least one new word that spans the length of the grid (horizontally or vertically). This check uses a large, comprehensive dictionary. The reason for this large dictionary is critical for player experience: if a player sees a word on the grid and forms it, the game must recognize it, even if it’s a bit uncommon. It’s incredibly frustrating for a game to not accept a word you know is valid!

- Recursive Exploration: If a swap is valid (i.e., forms at least one new word), this new grid state and the move that led to it become a new “node” in an exploration tree. The process then recursively explores all valid swaps from this new state, and so on. This continues until no more valid moves can be made from a state, or a predefined maximum search depth is reached.

Step 3: Analyzing the Tree
Once an exploration tree (or a significant portion of it) is built for an initial grid:
- Calculating
maxDepthReached: For every node in the tree (each representing a game state reached by a valid move), the generator calculates themaxDepthReached. This value signifies the length of the longest possible sequence of further valid moves that can be made starting from that particular node. - Determining Overall Puzzle Depth: The overall “solution length” for the puzzle (which the frontend knows as
gameData.maxDepthReached) is the highestmaxDepthReachedvalue found among the initial possible moves from the starting grid. This represents the longest chain of words the player can achieve. - Filtering Puzzles by Length: We use
RequiredMinTurnsandRequiredMaxTurns(configurable parameters for the generator) to filter these potential puzzles. Grids that lead to solutions that are too short (not challenging enough) or excessively long (potentially too tedious) are discarded.
Step 4: Word Dictionaries
This is where the two-dictionary approach comes into play:
- The Large Dictionary (for Gameplay Logic): As mentioned, this is used during the tree exploration step to ensure any valid word a player might form is recognized. At the time of writing, the large dictionary has 129,493 words in it.
- The Smaller, Curated Dictionary (for Puzzle Quality): After a potential puzzle is generated, the generator collects all unique words that appear in any valid path within that entire tree. These words are then checked against this smaller, more “usable” or common dictionary. If the given puzzle uses words that are too obscure or too obscene then the puzzle is discarded entirely. Many potential puzzles are discarded from this check. This is a key step to ensure the final puzzles feel fair and use vocabulary that players are likely to know or find satisfying to discover. At the time of writing, this dictionary has 6,956 words - an absolutely tiny amount compared to the large one.
- Controlling Word Variety: Another filter is
MaxUniqueWords. If a potential puzzle contains too many distinct words across all its possible solution paths, it might be too chaotic. This parameter helps keep the word set focused.
Step 5: Concurrency
Generating a single grid, building its exploration tree, and then validating it against all these criteria can take time. To find enough high-quality puzzles for daily release, I needed to process many initial random grids. Doing this sequentially was quite slow, so I ended up splitting up the work by using go routines. This greatly improved the throughput. It’s honestly so nice to have a highly parallelizable, CPU-bound problem to work with. It’s a nice break from the world of the web where I/O is typically the bottleneck.
Step 6: Outputting the Puzzle Data
Once a grid and its exploration tree pass all the filters, it’s deemed a “good” puzzle. The generator then outputs JSON with the details about a puzzle. To illustrate this, consider a simplified example with a single possible move for illustration purposes:
{
"initialGrid": [
["i","s","w","y"],
["e","v","a","p"],
["r","a","b","a"],
["h","l","l","a"]
],
"wordLength": 4,
"maxDepthReached": 1,
"explorationTree": [
{
"move": {
"from": [1, 0],
"to": [1, 1]
},
"wordsFormed": ["seal"],
"maxDepthReached": 0,
"nextMoves": []
}
]
}
initialGrid: The starting letter configuration.wordLength: The target word length for this puzzle.maxDepthReached: The length of the optimal solution path(s).explorationTree: The full tree structure, containing all valid moves, the words they form, and themaxDepthReachedfrom each node.
This JSON file is then what the React frontend loads each day to power the game you play. This is what an extremely simple grid looks like, with only one valid move from the initial state.
Lessons Learned
- Dictionaries are Key: The quality and scope of your dictionaries profoundly impact both gameplay fairness and puzzle quality. The two-dictionary system was vital.
- Iterative Refinement: Level generation isn’t something you get right on the first try. It requires constant tweaking of parameters, testing, and playing the generated levels yourself.
- Concurrency is Your Friend: For computationally heavy tasks like this, leveraging concurrency (like Go offers) is almost essential for practical generation times.
- Define “Good” as early as you can: Having clear criteria for what constitutes a good puzzle (solvable, right length, good words) helps guide the entire generation logic. I was lucky to have my wife, who’s a daily word game solver as a test user. Her feedback was (and is) invaluable. Making a game is an iterative process. A lot of times you legitimately don’t know if the game you’re making is fun. Who knows, maybe I made a game only my wife loves. And honestly? If she’s the only one who loves it, that still feels like a win. (But I do hope you’ll enjoy it too.)
- Tools to help testing are worth it: I didn’t mention this yet, but I have some tooling now to make testing a lot easier. Not only do I get clear display of the solutions (cheap mode!) but I can push a button and have the game played for me. This has helped a lot when I needed to get to certain game states quickly.
- Data structures and Game Design: I really love how this game relies heavily on computer science fundamentals and data structures. At the end of the day this is just a non-obvious tree traversal with a UI on top of it.
What’s Next for wordseq’s Puzzles?
I think there’s a lot of additional things I can use to judge the difficulty of a given grid. I could judge how often completed words switch rows for the next word, or (if possible), how often it alternates from rows to columns. Often, the puzzle will be easier when it’s only one row that is constantly updating. Changing one letter of an existing word is a lot easier for a mind to handle than re-evaluating the whole board every turn.
There’s always more refinement that can be done with the dictionary. The small dictionary’s pretty solid now, though an occasional spicy word still sneaks through. Oops.
On the frontend side, I feel like I’m getting close to a decent interface. I want to build an “infinite mode” where you can play random levels (identified by an ID so you can link them and go back to those puzzles later). I actually think this wouldn’t be too crazy with the way the components are laid out now.
I’m also contemplating how hard it might be to implement a Danish version as I am learning Danish.
Conclusion
Building the level generator for wordseq has been a fascinating journey into algorithms, data structures, and the subtle art of puzzle design. It’s a complex system, but seeing it produce fun and challenging puzzles each day is incredibly rewarding.
I hope this peek behind the curtain was interesting!
- Play wordseq daily: wordseq.com
- I’d love to hear your feedback on the puzzles or any thoughts you have on level generation. Drop a comment below or find me on Blue Sky or Mastodon!
Thanks for reading!
About the Author
